Detect a failure before it happens
“Detect a failure before it happens.”, “Solve problems before they occur and before they affect your business”. These are the rules that form “The new paradigm of monitoring”, which is about looking into the future and predicting failure situations. Simple forecasting techniques such as trend analysis or scenario based simulation make this possible.
Always available
IT systems need to be looked at and planned as an asset that is always available. 100% availability is currently a default (expected) key performance indicator (KPI). Based on this premise, enterprises can concentrate on monitoring their core business, instead of monitoring the IT systems that support it.
Five sub-domains
We believe that the monitoring domain can be split into 5 sub-domains. The Delivery Rationalization Framework will provide the means to assess each of the sub-domains. The assessment will define the maturity level for each of the sub-domains independently or combined for the overall monitoring capability of the enterprise. The five sub-domains are:
- Infrastructure
- Applications
- Services
- Use cases
- Business
Infrastructure
Infrastructure monitoring takes care of monitoring infrastructure like file systems, memory, CPU, network, etc. As stated before, monitoring is not just about detecting, but also about avoiding failures. Dynamically upscaling and downscaling these parameters is a widely available practice in cloud solution service providers. If your enterprise cannot do it, buy the service.
Applications
Monitoring applications is about making sure that all your enterprise applications are up and running at all times. With regard to monitoring applications we need to separate two different categories
- COTS (Commercial of The Shelf) applications.
These applications usually bring their own monitoring capabilities. Some of these applications are also available as cloud services. Whether you do it on-premise or in the cloud, your application monitoring should be part of the package solutions you have built.
- Non-COTS applications.
If you build the application yourself, you need to ensure the application can be properly monitored and can keep itself running with minimal intervention.
Services
Services need to be looked at in the broader sense of the word. It is not only related to the context of SOA. Services are usually provided by applications, and therefore any application downtime has impact on the services they provide. It is however possible that some services of a perfectly healthy application are down. Monitoring services is about providing the means to ensure that all services under our control are constantly available.
Most architectures are dependent on external services that are not controlled by the enterprise. Any dependencies to such services need to be carefully handled as it is not part of our domain to ensure their up-time. There are several ways to handle this situation depending on the details of the service
In the context of SOA, re-utilization is key for measuring the success of the architecture. Some companies have perfected the use of SOA and therefore the re-usability of their services. This success brings the challenge of monitoring composite services. Ensuring that these services are available is done by ensuring that the services they use are available. When defining the service monitoring strategy, these dependencies (or sometimes hierarchy) need to be taken into consideration.
Use cases
A use case is the first building block that starts making sense to business. A use case can for example be “A user requests product ABC in the web-shop”. Business teams will understand use cases. The implementation of use cases is usually translated into service invocations and involve several applications. Use case monitoring is the first phase in our stack where the word “monitoring” actually means configuring a set of rules that define wether or not a use case is available. These rules are based on infrastructure, application and service availability.
Business
Business monitoring is also known in the industry as Business Activity Monitoring (BAM). BAM provides the means for enterprises to analyse their current efficiency. Good BAM solutions will measure performance of business processes, detect their problems and exception cases. Business activity monitoring provides the means for diagnosing problems and identifying potential points of improvement in business processes
As in the famous Steve Jobs Stanford Commencement Speech from 2005, BAM is even a bit more than simply connecting the dots. Use your past to learn, but also use your past to predict the future and correct issues before they happen.
Predicting Impact
By looking at a visual representation of all monitoring levels, we can see how easy it is to understand the impact that each level has in the next level. The control that enterprises get out of this structured monitoring approach is a key driver for Success
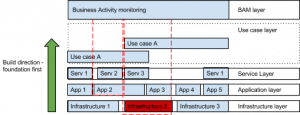
The red dotted line shows the impact of having the “Infrastructure 2” unavailable. The picture above is very simple, but it clearly shows that the lower we get in the stack, the higher the impact in the business processes becomes.
From my point of view, IT must provide flawless platforms that can predict potential trouble points, and make the necessary adjustments to avoid them. Predicting flaws will enable us to eliminate them.
Other relevant DevOps content
- BLOG: Red Hat – OpenShift Day-2 Ops from the trenches
- REPORT: 2018 State of DevOps Report – DevOps Research Assessment
- OFFER: DORA – DevOps Research and Assessment
- BLOG: Observability in OpenShift with Prometheus
- WHITE PAPER: The Digital‐Native Enterprise – The Red Hat and Devoteam Success Formula
- BLOG: Shared continuous delivery toolchain, the silver bullet?
- NEWS: Atlassian Gold Solution Partnership for Devoteam
- INFO: Our CALMS approach towards DevOps
- CASE STUDY: Improving the CIO delivery cycle at Liberty Global
- BLOG: Monitoring to reduce Mean Time To Recovery (MTTR)
- EBOOK: API Strategy and Architecture
- EBOOK: DevOps Perspectives
- OFFER: DevOps and Culture
- OFFER: Continuous Delivery
- CASE STUDY: Same meat, different gravy
- BLOG: Become a high performing organization with DevOps as business enabler

