
This integration required it to work on certain times and in order to be in control of the output, I used a scheduler and set the parameters.
The original design of the application was also schedular triggered API invokes and RPG call over the system API to AS400 system.
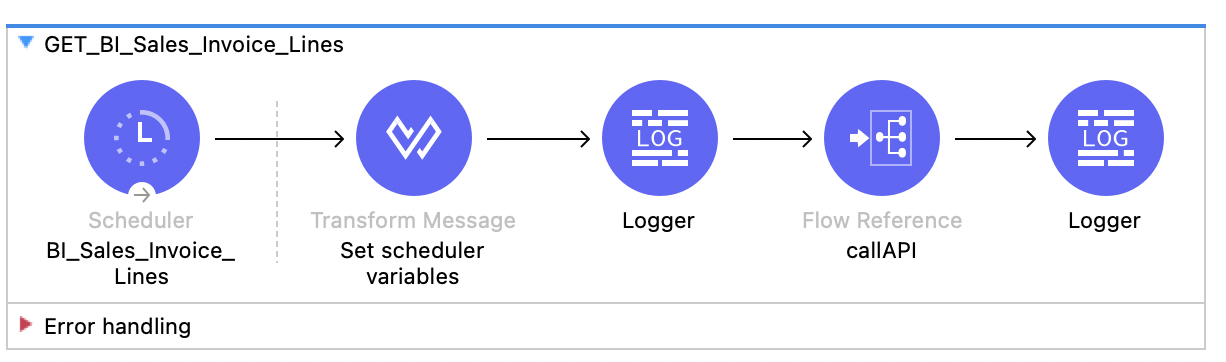
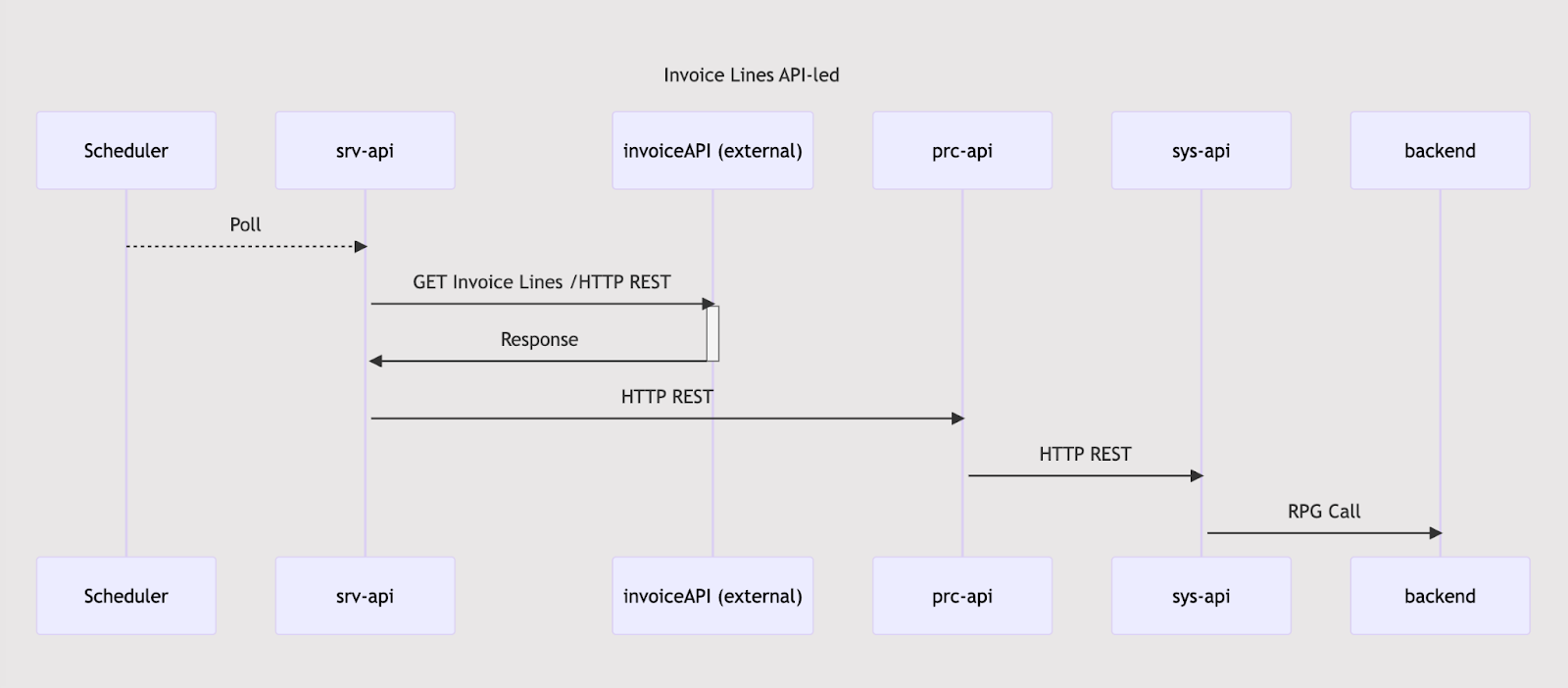
This design was already implemented with a scheduler to retrieve data in pieces. On every recursive action, it calls for 50 invoice lines and goes on until the response is an empty array. It was working but there were a couple of issues:
- Persistence issues: Average daily data amount is around 10K. It may seem an API can handle this in one go, the payload is too big because of the amount of objects on every invoice line. So while using Cloudhub, it requires at least 1 vCore or even more to handle such load. Therefore it has been designed to get the invoices piece by piece (pagination) to control the memory consumption on the application. That is a valid approach of course but then we need to persist the pagination info for data integrity.
- Process Layer Overload: Process layer is not only used by this service (experience) layer application, so it is also overloading the process layer and creates a bottleneck.
- Backend Availability: Backend system is ERP and an old one with no scalability option and on-premise implementation, so it is wise to prevent it against stress.
Let’s discuss the possible solutions for those items:
- Fastest and easiest way to persist data on Mule is Cloudhub Persistent VM queues. But Cloudhub Persistent VMQs extremely degrade the performance (10x or more) and it is not suggested for 1 worker implementations or for achieving reliability patterns. It is more suitable for persisting only the pagination data on VMQs. So we will not lose the pagination info in case of breaking errors. On the other hand it is not ideal to persist whole payload on VMQs because you can easily hit the limits on high throughput. Also retention time is 4 days and cannot be configured which closes the door for longer persistence specifically for dead-letter queue approach.
Then there are enterprise grade message brokers such as Active MQ, Anypoint MQ etc. These are much more flexible and reliable vs Cloudhub VM queues. Kafka also has this ability and also replayability.
- In order to prevent overload on the process layer, we can use API Manager capabilities such as spike control or throttling or rate limiting, but all of these can prevent the process layer for a limited time or they will reject it completely. A better approach to that is consuming messages at its own pace, which brings us to Message or Event Brokers. Both of them are fine again for this case.
- Sometimes we find that we require some old batch to be reprocessed due to backend issues. With API-led we have to enable an endpoint so in such cases we can configure a postman call to retrieve all the invoices again from the beginning. Because of that, Kafka is a better solution because it persists the old messages (events) even after those are read. You can put retention time as forever (log.retention.ms = -1) and replay from any offset number or date.
These are not solely the reason that we decided to go with Kafka, there were a bunch of other issues that need to be addressed. After long discussions, Proof of Concepts, Tests etc, we landed on Kafka.
Nevertheless for the first design we discussed VM queues, but we discarded it because of two reasons; a- Reliability (also referred at No:1) b- Possibility to migrate Cloudhub 2.0. Persistent VM queues are not supported on Cloudhub 2.0.
Then we started comparing Message Queues and Event Streams like Anypoint MQ, Active MQ, Azure Event Hub, Solace, Confluent and Kafka Community Edition with Axual or Conduktor to manage.
For its easy implementation I used Confluent cloud for Event Streaming. First design was only to implement Confluent (Kafka) between flows to not to disturb the already complex process more.

Because the original design was following the 3-layered API design, every page was asking for only 100 invoices from the API in order to prevent the process layer API. But that approach created an overhead with the components between API call and publish to Kafka. Also stall the process between the API calls to retrieve the data from the 3rd Party App while doing pagination and that causes elongated memory pressure, even getting “Too many nested child contexts ..” which forces us to create a new design approach.
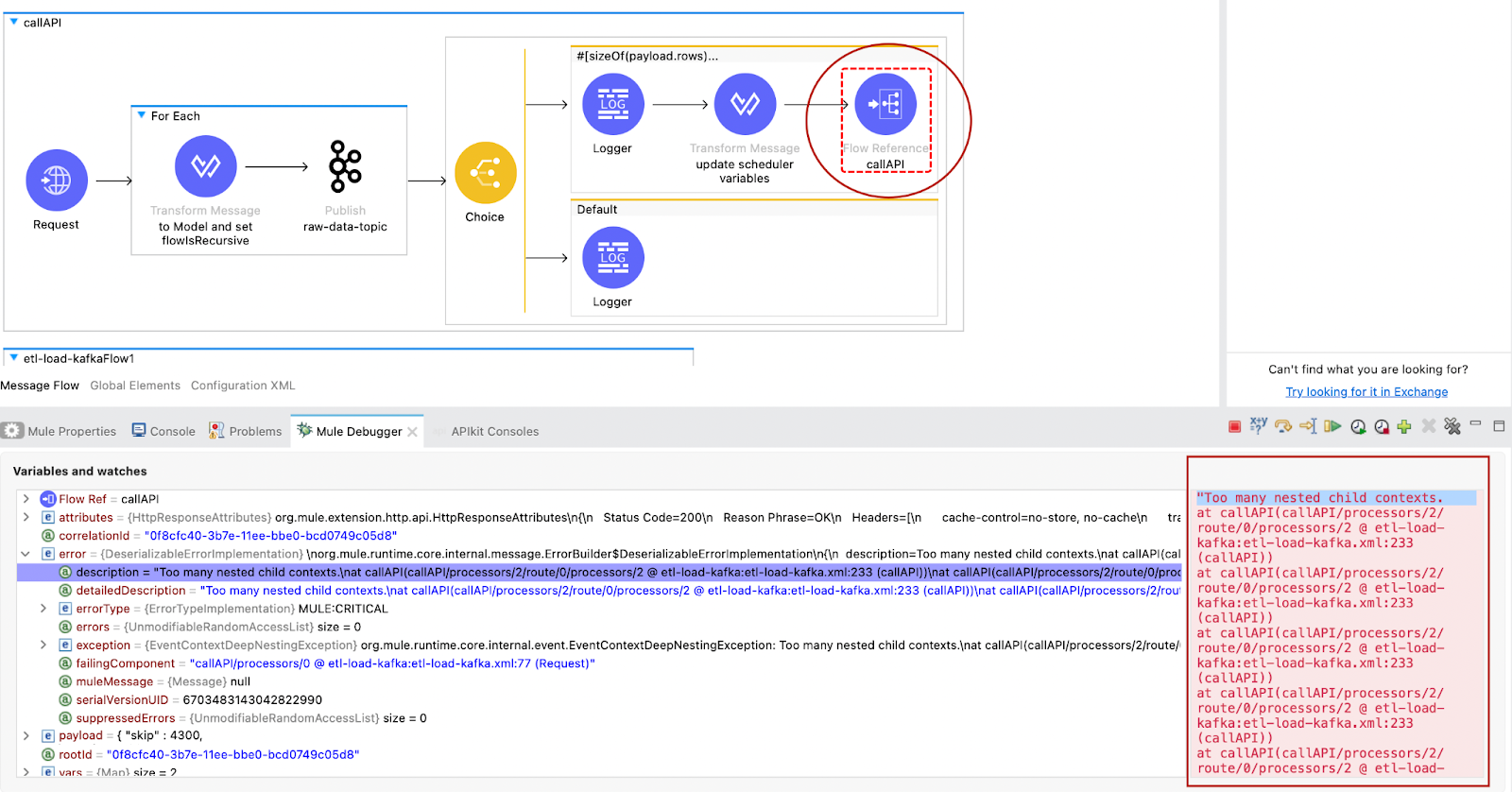
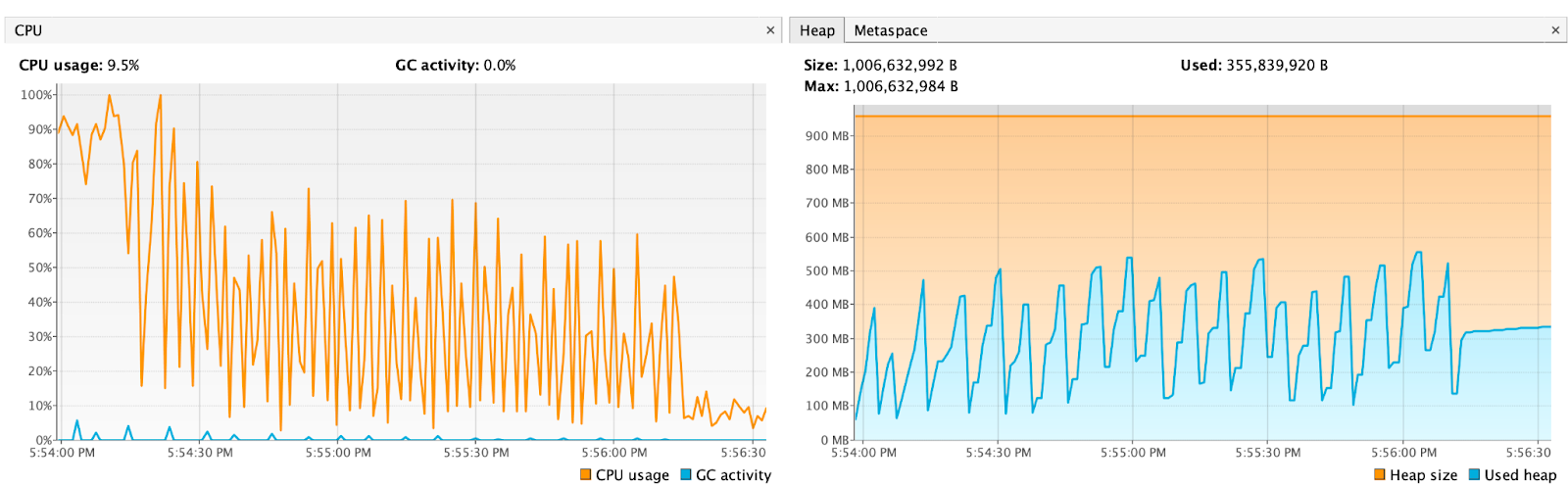
It is not clear in MuleSoft articles for how many recursive flow calls cause the error, but what I observed from the Kafka topic, it kicked for me around 44 calls (every loop has 100 events). Also we were only able to process 4400 events in 1 minute 57 seconds.


