
The API-Led is still a big deal in an ever-changing market, but no system has limitless resources and every new day brings new resource challenges. Therefore while using synchronous applications for user experience is still a good idea, processing millions of data may require going asynchronous at least in order to keep the backend safe and sound. In the end, as middleware that is one of our jobs, right?
While EDA is good with loose coupling, persistence, reliance, performance with greater scales, it has disadvantages on standardisation, governance (asyncAPI may help on these 2 items ), trackability and consistency. So bringing both an API-led mindset and EDA can bring great value to your enterprise.
There are quite a few options that we can choose, even more than I tried to show here and you may even increase the performance further. I tried to reveal the correlation between different approaches, results are not surprising actually but I hope it will help you design and fine tune your applications. It helped me where to look for more memory or more CPU utilisation happens and how it correlates with total process time. I combined the Visual VM outputs into a graph with total processing times.
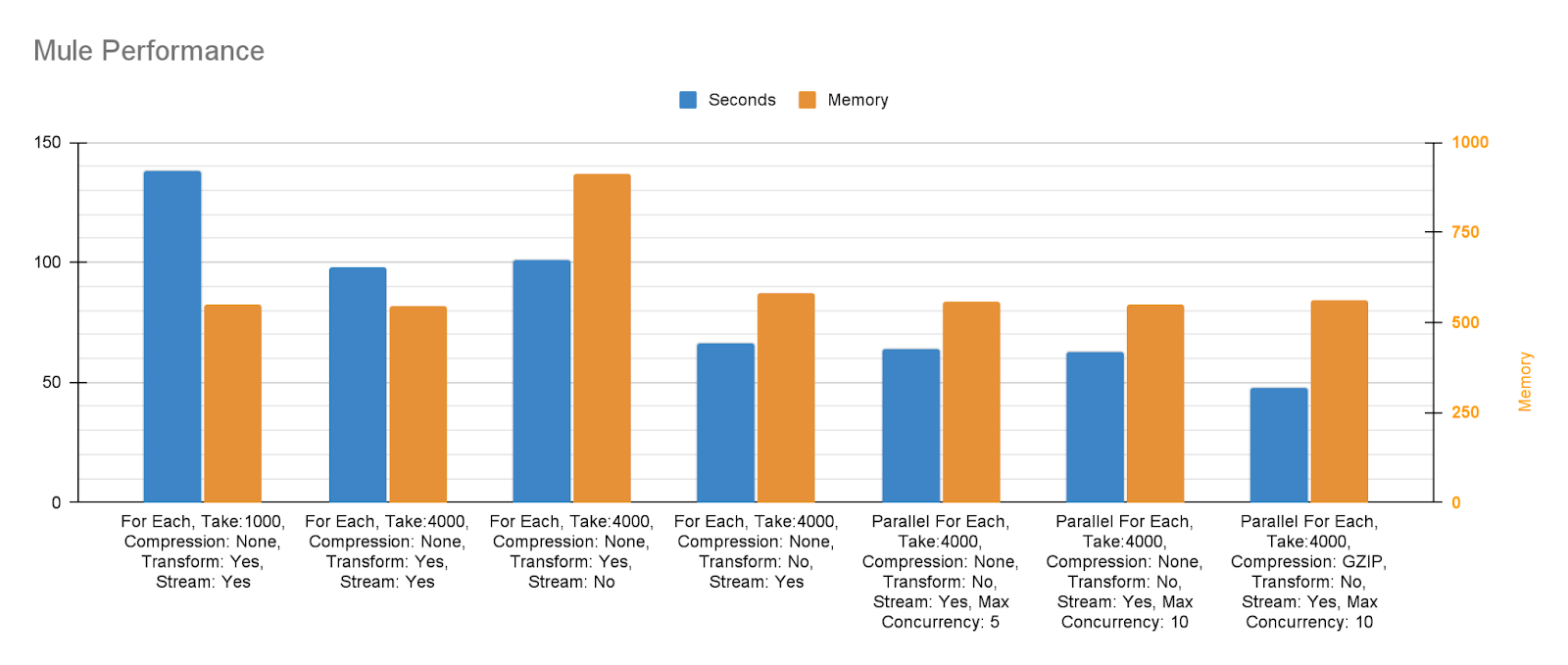
I can summarise my conclusions like below;
- If it is vital that the process is async, and you are using CloudHub, do not depend on Mule’s VM Queues. Find other solutions such as Anypoint MQ, Active MQ, Azure Event Hub, AWS SQS, Kafka etc. Every one of it has different upsides and downsides. I have created a comparison chart for a couple of these solutions in the process of picking an Event Driven enabler. I am planning to publish it as an article in the near future.
- Take in mind the 3rd party dependencies in the beginning such as the API or FTP Server you need to get the data. There is a chance you will hit their limits before you hit your limits. So you can design accordingly.
- Use HTTP Stream Response in such API call cases, so you can distribute memory consumption through time more evenly.
- In my case I have to break down payload per item, so the “deferred” option didn’t help me but if you are loading the data on bigger chunks, don’t forget to enable this option so on every component you can continue to stream to the next one.
- For Each and Parallel For Each didn’t change the outcome for me. That is either because I am using Confluent as a free-tier and they somehow limit the process or as far as I know Kafka connector does not commit the events until some threshold. So even though I used the “For Each” component, it was not committing right away. Instead waiting for some events to be submitted and then it commits as a batch. (see “batch size” section) Therefore I may have been getting the similar results from “For Each” as in “Parallel For Each” Maybe it would be a good idea to test with a batch process component as well as changing the Kafka Connector’s batch size for performance optimization.
- Because of the 3rd party API limits, I was not able to use almost half of the available memory. That might not be the case for you in bigger payloads and that may affect the design approach. Like on higher volume of payloads, streaming will be much more important.
- I also tested with divideBy operator instead of for each, out of curiosity; no use. Also I tried repeatable and non-repeatable streams I used, but that didn’t change the outcome again and non-repeatable streams actually do not work for me because I need to count the response payload array items in order to decide whether make a new call or finish the process.

