Part 1: An introduction of the framework
This blog is the first of a series of five. It provides a framework of how to implement process models obtained from process mining to help decision-making for Scrum teams & organizations. The framework helps Scrum teams prioritizing stories, estimates the duration of each story and allows to share useful information with other Scrum teams facing similar challenges. In this article, an example is used to help you understand how to implement the framework. In part I (this blog-post) the framework is introduced, and in later sections, detailed hands-on examples will be present. For now we focus more on the concept.
Why would you want this?
Important goals of DevOps are to reduce “risk and rework”, which is in line with the lean paradigm. Extensive literature on the DevOps lifecycle itself and its philosophy can be found in this Top 10 list of best DevOps books. Reducing risk and rework is often done in an agile fashion -e.g. implementing the Scrum framework, Kanban or other management frameworks or methodologies. An agile work fashion is defined as the ability to be flexible, allowing to deal effectively with change. Agile working environments state that teams determine their own goals and tasks. Experience is the main driver in this decision-making process. Scrum is an empirical-based process. However, it doesn’t provide an empirical data based Decision Support System (DSS) for agile work-environments to help teams effectively allocate their resources on the team level. Whereas ERP systems and other tools are highly available for corporate decision-making. The information system landscape increases in complexity. Therefore, it would be useful to have guidance in making smart decisions regarding resource commitment.
More about DevOps
Implementing DevOps creates the mind-set, tools & processes to turn ideas rapidly into new and enhanced features. With more than 50 certified DevOps consultants, we help our clients in winning their digital battles every day.
How?
This blog-post provides a framework to implement a Scrum DSS on the team level. Simplified, the framework’s objective is twofold. The first objective is to help decide which tasks, and in what order, should be put on the backlog (phase 1 and 2) to maximize value creation for the business processes. The second objective shows how the work “done” by the Scrum team improved the process it worked on. Later blogs explain how the second objective can be shared among Scrum teams, allowing Scrum teams to learn from each other.
The DSS is created by combining data from both the Scrum process itself and data of the business process. First, the business process data is used to create process models with process mining. These models show the workflow of the business process (figure1). Second, the event-log of the business process is extended with the data gathered in the Scrum process. This allows for filtering in the process models in a similar fashion as Business Intelligence (BI) tools. The main difference is additional filtering capabilities, that allow slicing the process model itself by simply clicking on a Node or connection in the process model. This allows for impact-assessments of previous tasks executed by the Scrum team in the current state of the process. This information helps the Scrum team to analyze and support the decision-making process for future sprints. In order to do so, all relevant data must be present and captured to determine the impact of the work done by the Scrum team. This is discussed in the Scrum process & Data section of this blog.
The Business process
One of the biggest current challenges in the DevOps realm is to update legacy apps and its infrastructure. In our specific case, the legacy application is a Price forecasting tool for several commodities. Figure 1 illustrates its current infrastructure. The forecasting tool is stored on a separate server (C) and all departments submit their data weekly from their own database (A & B) on separate servers (A & B). When the application receives all the data stored in the database (C), it provides weekly forecasts. The sales forecasting app offers a variety of forecasts, meeting the requirements of each specific business unit. In total, 200 different forecasts are made on a weekly basis. This process is depicted in Figure 1. However, nowadays the business wants to move to an automated cloud environment where the data is centralized, automatically stored and processed by the forecasting app into forecasting reports and clean data for BI tooling. The business aims for a cost-effective solution. The main purpose of the innovation for the business is to use the data for real-time monitoring of sales with Business Intelligence (BI).
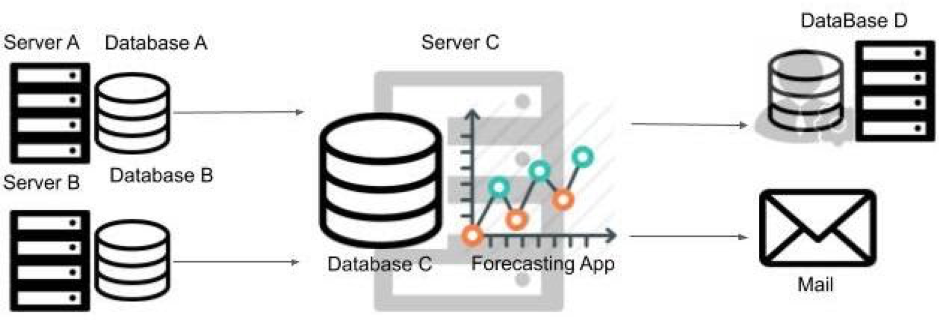
Figure 1. Legacy app business process.
The Business process Data
This section explains the data set obtained from the business process, involving the legacy app to create a process model. In order to create process models a minimum of three variables is required. The case_id being the unique identifier (a single forecast for a business unit). The event informs what action is taken (e.g. data sent from the business unit server & data stored in the forecasting server). The timestamp specifies the date and time the event occurred. Together these three variables are called the event log. This is all we need from the business process to form the most basic process model. More importantly, each element (connections and Nodes) can be clicked on to specify your analysis (figure 2). With the most basic event log, the analysis shows the frequency, meantime, and the suffix (the next event) of events. There are several tools out there to help you with it. A free version that I personally like is the python module PM4Py – Process Mining for Python. If you want more information concerning process mining, this is a useful link: LNBIP 99 – Process Mining Manifesto.
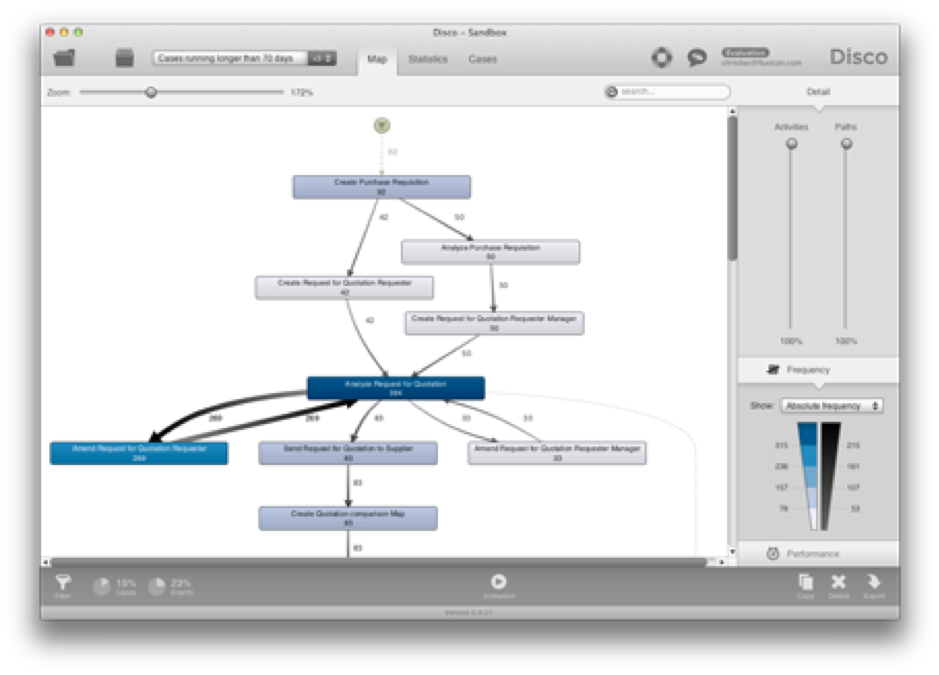
Figure 2 (obtained from Disco, a simple quick limited feature tool for quick and simple insights!)
The event log before the Scrum sprint:

The Variables CPU-usage & CPU-available are included to allow a comparative analysis at phase 2 of the following sprint. This is explained later in this blog.
The Scrum Process & Data
This blog-post assumes readers have prior knowledge about Scrum. Please consult this webpage for more information when you have no prior knowledge about Scrum.
Let’s assume that the Scrum team is using this approach for the first time. However, like Scrum, our framework is iterative and all Scrum data of sprints is stored to be used for future sprints.
The process model obtained from the business process data is used in the sprint planning and backlog creation of the Scrum process in phase 2. The process model, like the BI tools, allows for extensive filtering. Additionally, sections of the process can be filtered to allow an in-depth view of the actual process. For example, a root cause analysis that informs where the biggest bottlenecks in the current process are. Let’s say we find our biggest bottleneck towards real-time processing is the transmitting intervals of 1 week from the business into the servers. However the Scrum team doesn’t know if the current architecture of the information flow allows for more frequent storage, let’s say every 3 hours. Therefore, in order to find it out, a solution must implement two new variables. This is the storage and upload capacity percentage (depending if the server sends or receives data) at the timestamp of an event. With proper filtering, the team can now see if the servers are capable of processing the desired amount of data (every three hours) over time. Additionally, the capability to do so for specific use cases or business units is automatically inherited due to process mining. This can be useful if different requirements are in place for different business units. There are, however, other tools for this. So This blog is the first of a series of five. It provides a framework of how to implement process models obtained from process mining to help decision-making for Scrum teams & organizations. why use process mining?
Scrum for business value: Are you ready to embrace change?
Reasons for Process Mining
- If data is present, process mining allows for the rapid development of insights, therefore valuable information for decision support is available in a matter of minutes.
- The visualization allows for an easy explanation to stakeholders with no IT background.
- Instead of merely expertise of the Scrum team and filtering the backlog, process mining is an empirical analysis that can supplement arguments of the decision-making of the Scrum team (to validate your hinge).
Defining the Objectives
First, the Scrum team uses its experience to formulate the requirements necessary to fulfill the business’s request. The Scrum team finds that it is possible for the business unit servers to handle the load of the upload and storage of the separate databases of each unit (figure 1, database A, B & D) but not for the central server of the forecasting framework (figure 1, database C). The team discusses two opinions. Option 1, move to a cloud environment with all servers to prepare for future requirements. Option 2, only move the limiting database D with to a cloud environment. They decide to go for option 2. The team finds it a best practice to start small and scale-up.
The next Step in phase two involves documenting measurements to assess the impact of the work “done” during the working phase. Now let’s set the measurement definitions to assess the impact for the sprint of our Scrum team Artifacts created by the Scrum team, during sprints, which can result in two different benefits for the business. First, it will result in a Cost-saving i.e. delivering the same value at a lower cost. This requires some subjective assumptions. For example, the resource costs made in the first sprint must be allocated to all forecasts done after the sprint. However, a second sprint will occur at a later point in time. How do we balance the costs inquired in the 1st sprint to future forecasts done after multiple sprints? A solution would be to depreciate the investment over a fixed period of time or a number of forecasts. If this is done systematically we can still use it to measure cost efficiency. Second, value enhancement for the business. For example, additional features that are valuable or business performance. In our example, we measure increased value by the capability of real-time monitoring. In other words how much CPU do we use and do we have left for data transactions between databases.
In our specific case we measure the capability of real-time monitoring with two variables:
- CPU usage per server used for an event
- CPU usage available for processing per server used for an event
The additional Scrum data will be matched with the process model after the sprint is completed. This is done by extending the event log of all future Case_id’s with the created variables. This requires additional data manipulation of the Scrum process data.
The next step is to ensure we obtain all relevant data of the Scrum process to perform an impact-assessment after the Scrum sprint. Now we have come at a vital aspect of creating a capable DSS, we need to document all tasks linking the Scrum process in a standardized fashion. Together with the impact-assessment measurement variables, they will supplement the business process event-log. Ideally, if the adoption of a DSS increases a uniform standard should be formed throughout organizations so that data can be shared among Scrum teams. For now, the blog provides some guidelines to follow.
- Use a digital Scrum board (link for such tools) that allows you to extract the data and make sure everything is related to the event log by including extra information in the form of variables.
- Create additional variables for each story that specify the goal of each story, the expected time it takes to complete, the sprint number and the cost of additional resources if available(i.e. Labour costs, software costs & hardware costs). Also, put a sprint number column in the event-log in the business process data after the sprint so that you know what the impact of each sprint is when you filter on a particular sprint with the process model.
- Be consistent with stories, try to be as concise as possible and goal-tags for tasks that are repeated throughout different stories. This allows for allocating a story to a specific goal (this will be discussed in the following blogs).
Processing the Scrum data gathered by using the guidelines with a process mining tool results in a process model like this example:
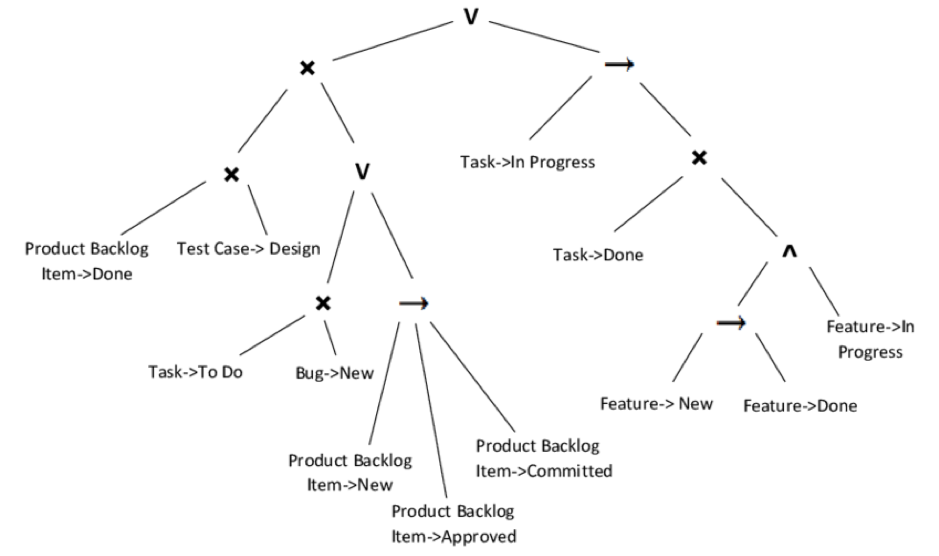
Obtained from Scrum sprint event-log

The complete business process event-log After the Scrum sprint:

In my next blog, I will implement the content explained in a detailed hands-on case study. If you have any questions, please contact me by email via the author section below.

