
In a production environment, it can be difficult to limit user access to sensitive data while still allowing them to do relevant searches and aggregations. Developers shouldn’t have access to personally identifiable data: names, emails, or IP-addresses, but giving them access to anonymized data can be of great help in troubleshooting.
Data analysts would like access to bulk data but most likely shouldn’t access sensitive information either. Technical support contacts need to access relevant data, but again, it should be as limited as possible. How to keep your data safe while still giving access to users?
Processing your data
If you are using Elastic, you should process your data with a tool such as Logstash, an ingest pipeline or similar and split your data into easily identifiable fields. Filtering by field is one of the most useful functions in Elastic in my opinion. Use it, it is such a powerful tool. Now that we can easily identify what data we have, check with your privacy officer on who should be allowed to access which data and let’s configure some user roles.
Configuring user roles and Field level security
In your Kibana security settings you can create roles for different user groups. The good thing about these settings is that it gives you very fine grained control. You can give access to entire indexes except a specific field, give access to only specific fields, use wildcards, and mix and match all these together. So even if your index contains sensitive data, you can still give a developer access to it by limiting the fields they can see.
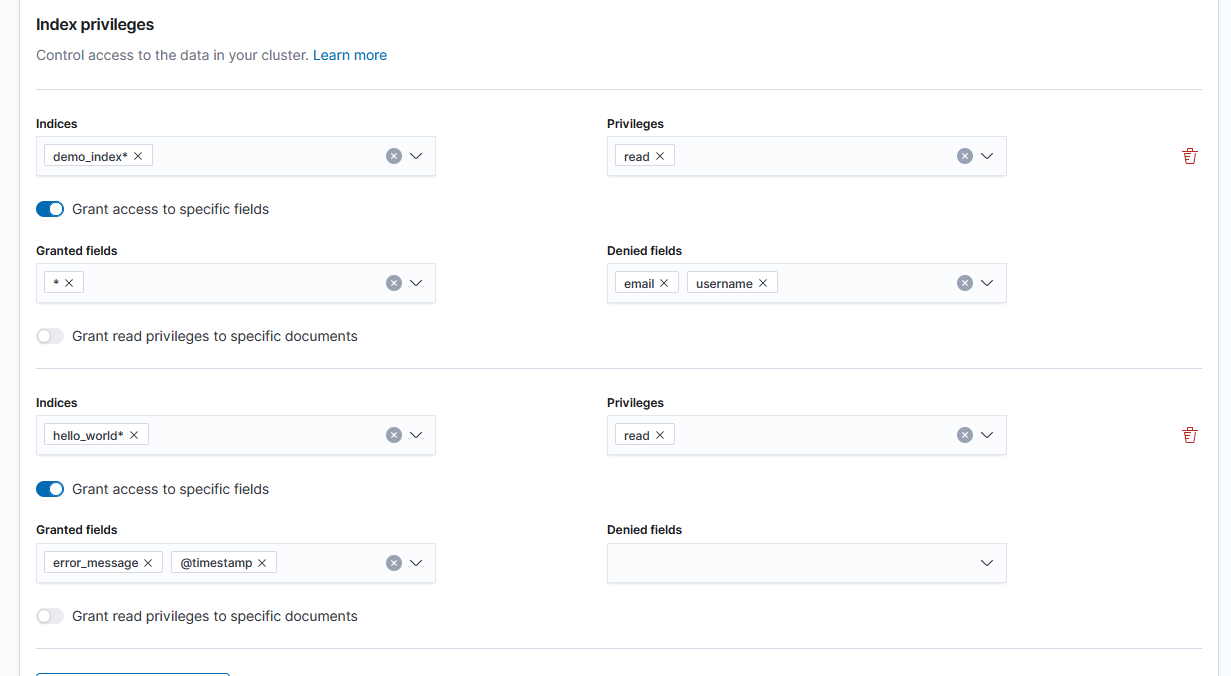
An example of giving access to all fields except specific ones and only granting access to a few fields.
Great, but this only gets us 99% of the way there, users can no longer see the sensitive data, but now they can no longer use this data as a filter either.
What if you want to count the number of unique emails, or need all data of a specific user, you can’t see either of these fields any more? The answer is data masking.
Data masking using the logstash Fingerprint filter
The Logstash fingerprint filter provides a way to do a one-way transform of a field. The great thing about this transformation is that the same input always results in the same output but cannot easily be reversed. In this way you can take a sensitive field like email as an input to create a new field called email_hashed.
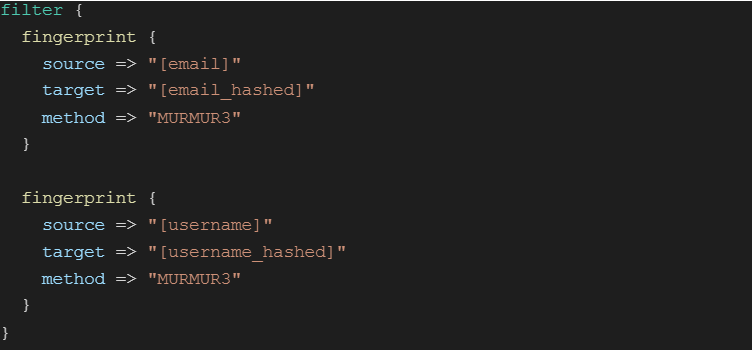
An example of using the fingerprint filter to hash an email address and username. I prefer the Murmur method as it’s fast and lightweight, but make sure it suits your purposes.
So now you can count the number of unique emails without actually having to know them, and see all data of a single user based on a hashed username value. Make sure to always check with your privacy officer even though a field is no longer human-readable. It is still a unique identifier that might require special consideration.

