
Modern IT Paradigms: Decentralization vs Centralization
There seems to be a conflict about the design philosophies of two of the modern IT paradigms. On the one hand there is the idea of microservice architecture. The idea that rather than being monolithic, systems should be made up of independent but connected parts. By giving these parts, or microservices, their own infrastructure and databases, you increase modularity and scalability, and easy development and maintainability.
On the other hand, the modern data paradigm depends on centralization. To facilitate analytics and ad-hoc querying, data needs to be gathered from the system and stored in a central data repository, like a data warehouses or data lake.
So one paradigm wants to centralize, the other to decentralize. How can these two be combined?
Tension between the two paradigms: why?
If there is only one source database, it is straightforward to regularly read data from the transactional database and store it in the data warehouse, and run reporting on that. However, the more of these source databases exist, the more complicated this process becomes.
It is not always the best approach to apply the solution for a single database to all of your microservice databases. In a monolithic database, you can safely assume that the database design will be relatively consistent. As a lot of parts of the system all depend on the same database, making large changes to the database design will have serious consequences to the system, and this will rarely happen unexpectedly.
In a microservice architecture, the microservices are designed to be self-governing and to have all the data they need. A microservice database only has one goal: to facilitate the microservice, and therefore should be free to change at any time to better suit the needs of the microservice. Because of this, you cannot make the same assumption of stable database design as you can in a monolithic system.
As the format and content of the data could change at any time, simply reading the data from your databases and writing it to your data warehouse might not always work. Instead, you need a way to remain up to date with the data of each microservice, without directly accessing the microservice databases. But how?
Solutions in Azure: Use a Messaging System
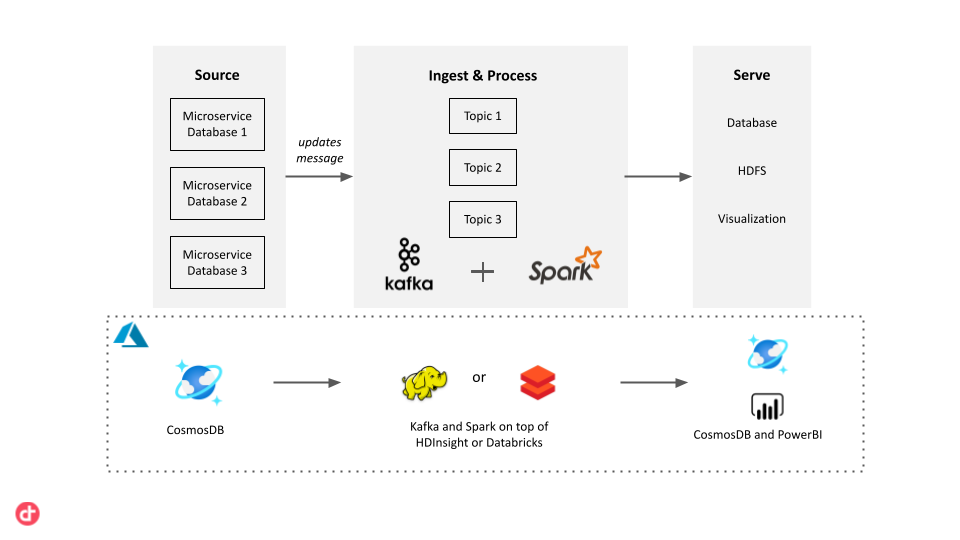
The issue of data warehousing in a microservice architecture can be solved through the use of a messaging system. We can use Change Data Capture (CDC) in the microservice databases and write the data changes to a specific topic of a messaging service. A pipeline can then easily pick up this message, process it, and apply the necessary changes to a data warehouse.
Azure offers various options for back-end databases, which can support front-end applications in multiple different data formats, depending on an application’s needs. For example, if we have a web app with document databases, it can be migrated to CosmosDB’s MongoDB API.
Open Source & SaaS solutions
We can use Apache Kafka for the messaging component. Whenever a microservice makes a change to its CosmosDB database, it writes a message to a Kafka topic. To process these messages, we can use Spark Streaming, which integrates with Apache Kafka, and can easily be run on Azure using HDInsight or Azure Databricks. Alternatively, we can make use of Azure’s managed services. For the messaging we can use Azure Event Hubs, which can be picked up and analyzed by Azure Stream Analytics. These managed services require less set-up and might offer more ease of use.
Once the data is processed by the streaming pipeline, it can be sent to the required locations. It can be stored back in CosmosDB, sent to a data warehouse, for example Azure Synapse Analytics, or streamed to PowerBI for real-time visualization.
Conclusion
This solution allows you to maintain an accurate, centralized and up-to-date data warehouse while also allowing all parts of your system to be self-governing.

