This is the second blog-post of my GCP technical series. In my previous post I outlined a way to use master_controllers to orchestrate Airflow jobs with Beam jobs that are dependent on each other. A limitation of only using a master_controller and individual beam_trigger DAGs is the amount of code that has to be put into the master_controller. This is especially the case when there are many DAGs to orchestrate.
The challenge: sub_controllers are needed
Suppose we have a collection of five Beam jobs we want to orchestrate using Airflow. The Beam jobs are dependent on each other in the following way:
- DAGs 1A, 1B, 1C are independent
- DAGs 2A, 2B are dependent on one or multiple of the DAGs in step one
Following this situation, some DAGs could be run in parallel. We can run all DAGs in step one at the same time and after all of them have finished successfully we can run the DAGs in step two. In order to keep the master_controller DAG file small and understandable, and to separate some logic we will introduce sub_controllers for each layer of DAGs that can be run in parallel. Therefore, we will have sub_controller_one (S1) to orchestrate jobs in layer one and sub_controller_two (S2) to orchestrate jobs in layer two.
Adding sub_controllers
As a recap from the previous post regarding master_controllers, the final design looked like this:
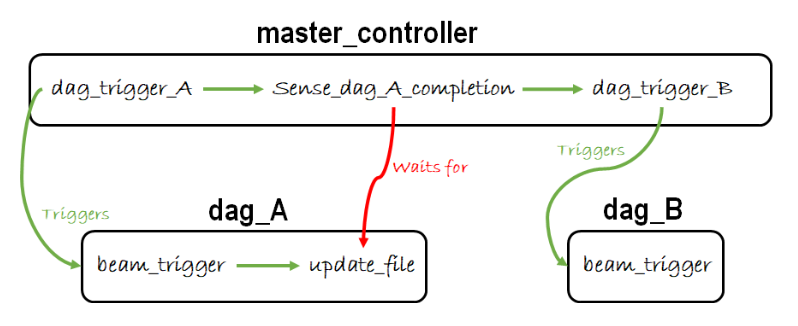
Furthermore, we set up an inbox and outbox in GCS to use for moving around sensor text files. If we want to introduce sub_controllers to this design we need to change some things. First of all, the master_controller will only be responsible for triggering and waiting for completion of sub_controllers. This means that, besides the sensor files for the individual beam_trigger DAGs we now also need to have a way to mark completion of an entire sub_controller (which is equal to saying that an entire row of beam_trigger DAGs have been completed). To easily distinguish between sensor files indicating the completion of beam_trigger DAGs and sensor files indicating the completion of an entire sub_controller we will add a folder to our GCS outbox for every sub_controller.
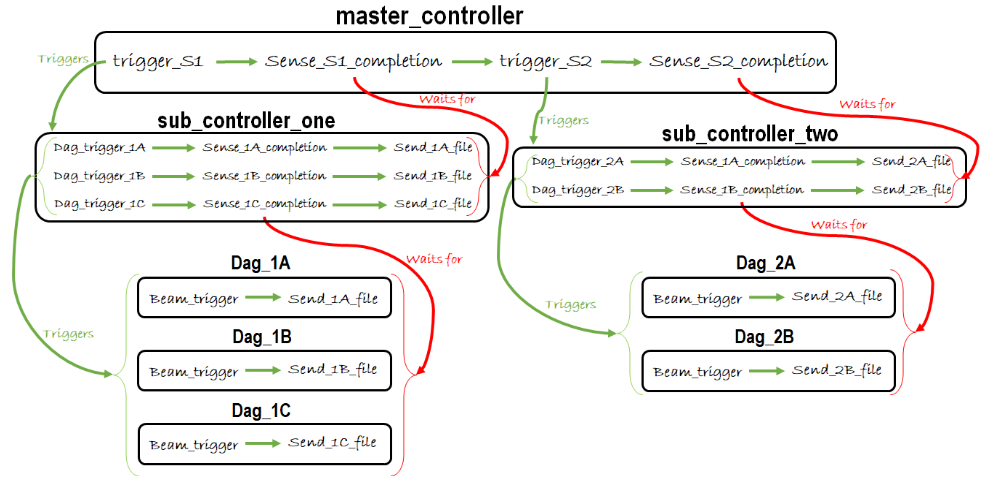
The entire set-up can work in the following way. Master_controller M will trigger S1. While S1 is running, M has triggered a sensor in the outbox folder specified for S1. This sensor waits for all DAG sensor files belonging to step one to be put in this folder.
S1 will trigger all beam_trigger DAGs simultaneously. Once triggered, S1 will start its sensor which is specified to wait for all sensor files belonging to DAGs in step one to be placed in the folder specified to receive sensor files (such as an outbox).
Individual beam_trigger DAGs will kick-off their Beam jobs. Once the Beam jobs are finished successfully, the DAG will transfer its own sensor file from the initial sensor folder (for instance, an inbox) to the outbox. As soon as a dummy file arrives at the outbox, the S1 sensor for that file will complete. This will trigger another file transfer in S1 which moves the respective files from the outbox to the specified S1 folder within the outbox.
The sensor in the master_controller waits for all files belonging to the Beam jobs in layer one to be placed in the S1 folder. Then the S1 sensor in M will complete, and S2 can be triggered.
Our new design looks like this:
Enhancing the code
With respect to the code itself, this is generally more of the same as mentioned in the previous post. However, if there are a lot of individual DAGs to run the code repetition can be very tedious. For instance, if six individual beams need to be triggered in step one, every one of these needs a trigger, a file_sensor and a send_file definition in the sub_controller. To make this more simple and short we can also use a for-loop.
We can make a Python module that reads a csv containing standard information every DAG variable definition needs (such as task_id, external_dag_id, etc.). The result of the module would be a dictionary containing information on all beam jobs to run. Then, per step we can select the information for every Beam trigger DAG we need and use this in different dictionaries for every operator/sensor definition.
In the code below an example is given of a for-loop in a sub_controller. This code assumes a module is made that returns a dictionary with all the necessary data.
beam_job_values = BeamInfo.parse_beam_info_csv()
first_job_layer = {key: value for key, value in beam_job_values.items() if value['order_number'] == '1'}
beam_trigger = {}
job_complete_sensor = {}
send_sensor_file = {}
for key, value in first_job_layer.iteritems():
beam_trigger[key] = TriggerDagRunOperator(
task_id=value['trigger_task_id'],
trigger_dag_id=value['trigger_dag_id'],
python_callable=conditionally_trigger,
params={'condition_param': True, 'message': 'Running GCS Sensor'},
dag=dag,
)
job_complete_sensor[key] = GoogleCloudStorageObjectSensor(
task_id=value['jc_sensor_task_id'],
bucket='bucket_containing_outbox',
object=value['jc_sensor_object'],
google_cloud_storage_conn_id='google_cloud_default'
)
send_sensor_file[key] = GoogleCloudStorageToGoogleCloudStorageOperator(
task_id=value['jc_send_file_task_id'],
source_bucket='bucket_containing_outbox',
source_object=value['jc_send_file_source_object'],
destination_bucket='bucket_containing_sub_controller_sensor_folder',
destination_object=value['jc_send_file_destination_object'],
move_object=True,
google_cloud_storage_conn_id='google_cloud_default'
)
for key, value in third_job_layer.iteritems():
job_complete_sensor[key].set_upstream(beam_trigger[key])
send_sensor_file[key].set_upstream(job_complete_sensor[key])
Note the use of an order_number to indicate the step to which a specific row in the csv belongs.
Note also that we are not using the ‘>>’ operator at the end to tell airflow in what order things should be orchestrated, because this cannot be used in a for-loop. Instead, we need something we can call such as the ‘.set_upstream’ and ‘.set_downstream’ methods. These methods essentially to the same as ‘>>’ and ‘<<‘.
Using the above approach, one only needs a single definition of every step in a sub_controller for an infinite amount of individual beam trigger DAG files. All that needs to be done is store the necessary information on every DAG to run in a csv and read this csv into Python as a dictionary.
In conclusion, this post builds on the previous post regarding the use of a master_controller in Google Cloud Composer to orchestrate complex jobs. When working with many DAGs which are partly dependent but can partly be ran in parallel, we can make good use of sub_controllers. Sub_controllers can contain the logic to run one step of the entire orchestration job.

