
The customer
Our European customer initially focused on consumer electronics before transitioning to healthcare technology and divesting its other divisions. The company is listed in both NYSE and European Stock Exchange. The primary objectives of the customers include optimizing the supply-chain, improving the quality of business operations, enhancing operational efficiencies, and reducing cost.
The context
Databricks to build the foundation of data platform
Before delving into the details of the most recent and fascinating challenge, let’s first establish some context and review past activities. Initially, the organization opted for utilizing the data warehouse capabilities and technologies natively provided by their hyper-scalers. This proved to be quite expensive given the multi-cloud ecosystem while still not satisfying all the needs of the end users. After a thorough selection process, Databricks was chosen as the technology to build the foundation of their data platform: transforming and consuming data in a Lakehouse implementation with Delta Lake as the focal point.
The creation of valuable insights in the supply-chain domain lacked
The main and significant challenge they faced was the timely access to data from their extensive SAP-dominated IT environment. Specifically, the absence of real-time capabilities and a limited extraction window hampered the creation of valuable insights in the supply-chain domain. This obstacle was overcome by introducing a change data capture tool that enabled near real-time replication of SAP data.
Following the successful ingestion of SAP data, Devoteam assisted the customer in significantly reducing costs through the implementation of best practices, such as regularly vacuum and optimize the delta tables, and more importantly migrating some workloads to more suitable infrastructure; leading to an impressive 80% saving on the specific bronze to silver workload.
The challenges
Monitoring and observability with Overwatch
We already migrated our customer to their new data platform. The next step was monitoring and observability in order to decrease TCO. Since the usage of Databricks grew quite exponentially, it was soon pretty clear that some monitoring was required. While Overwatch served as the best solution back in 2022, Databricks System tables now offer most of the necessary information to perform cost-saving measures and facilitate auditing; System tables indeed provide all the required information in a simplified manner without the extra components required for Overwatch.
The pitfalls of data mesh
At this point in time, the data landscape is robust, with flexible data ingestion and the adoption of the data mesh paradigm enables different domains to generate insights. Like any approach, data mesh can introduce some pitfalls, especially in the early adoption phases when the focus is on generating insights and value; it is not uncommon for data silos to reemerge. For instance, two different domains can rush into the creation of gold tables using the same information from the silver layer leading to a situation similar to the one depicted below:
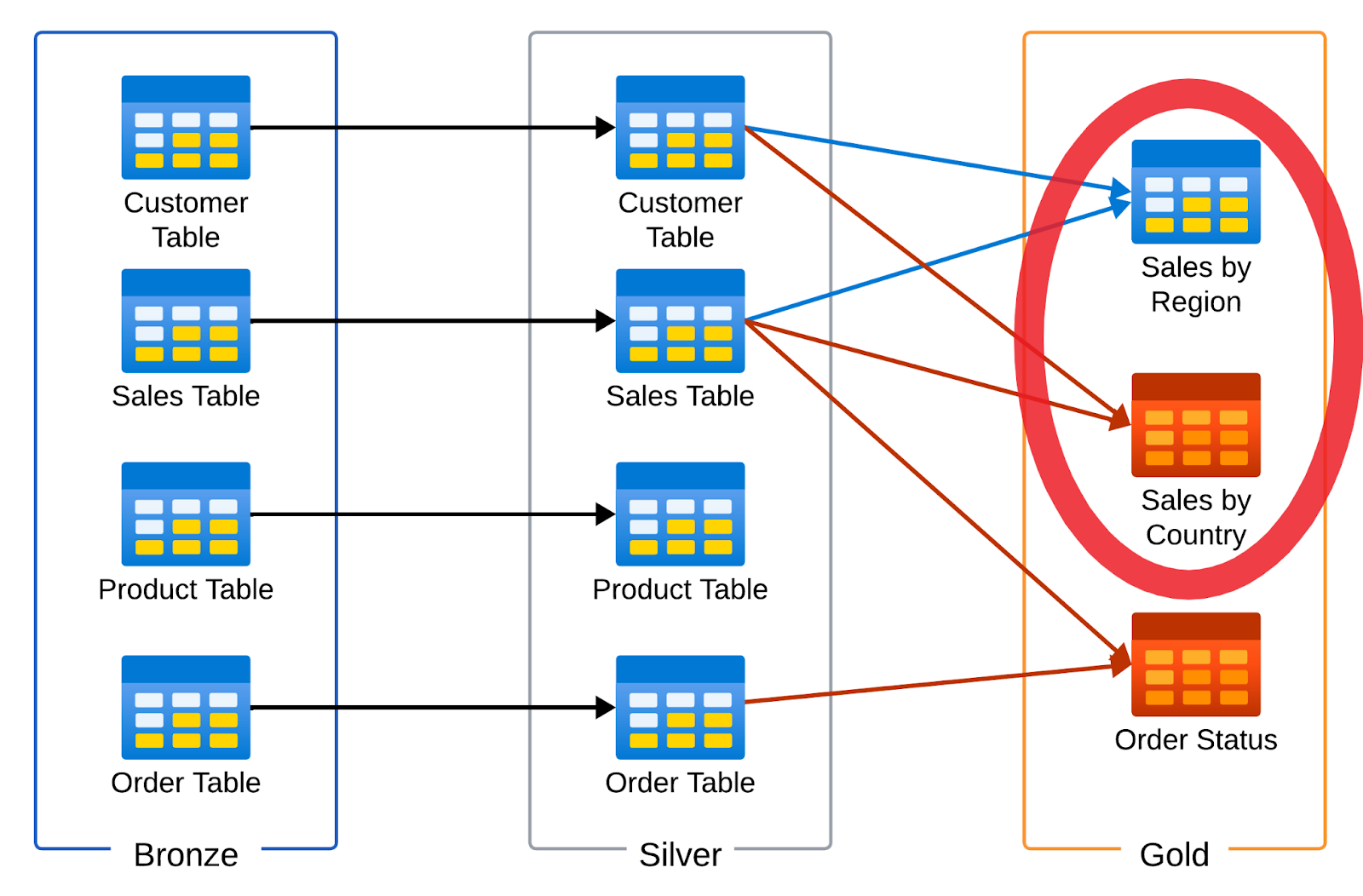
It is quite clear from the context that both the Red and Blue teams may have inadvertently produced duplicated datasets, consequently inflating costs for both storage and computational resources.
The solution
The image above offers insights into addressing this issue: data lineage. Data lineage indeed visually depicts how data flows across different datasets. While Databricks with Unity catalog provides data lineage per table, encompassing only the downstream and upstream tables, a complete lineage of all the datasets is required to grasp the broader context and identify potential duplicate datasets. To achieve this objective, we leveraged a new feature from Databricks: the system tables, particularly the access schema that includes table and column lineage.
Using the information in the system tables, we successfully created several entities including:
- All the available tables (along with their properties) unaffected by user permission unlike the information_schema;
- All the first-degree lineage information (in layman’s terms, all the tables that have source tables including the names of the source tables);
- All the tables that potentially are duplicated, as exemplified above, including column lineage.
The results
With the delivered Spark application, the customer can now identify and address the potential duplicates with the required teams, leading to a more efficient and cost-effective situation. Additionally, the solution enriches the centralized data catalog and helps tackle potential anti-patterns, such as using the bronze layer to create gold tables.
Quantifying the business benefits is challenging due to the complexity of the resolution process involving multiple parties. Nevertheless, it already serves as a method to prevent similar issues, resulting in a positive ROI.

