Imagine building software automatically on commit (great!) and deploying it to development and test environments automatically (also great!), only to realize that all artifacts in your artifact repository are version 1.0 (not so great). So what to do when a rollback is required? Scavenge machines for the correct code package? Should you build it again from source code (but what was the commit again)? All kinds of risks are introduced when moving around software packages without proper versioning.
DevOps is all about continuous improvement and at Devoteam we do just that. With this blog I want to show how we approached a case, like the one described above, for a customer running a large number of Tibco applications in production.
Situation
One of the explanations for this situation was insufficiency of the build platform, combined with rapid growth of the number of applications. A lot of effort went to developing and testing applications, while maintenance of the build platform was neglected. Suddenly, key developers were executing rollbacks manually because only they knew where the code was located.
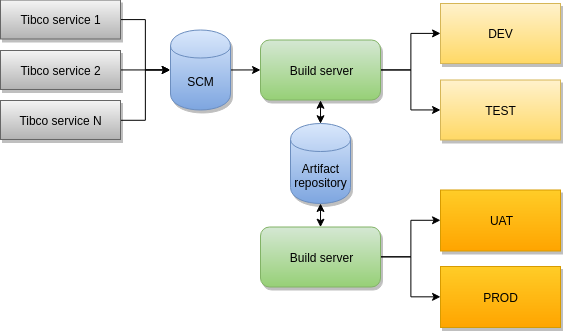
Simplified drawing of current build/deploy pipeline.
The artifact repository in the drawing above contains only one version for every artifact it holds. This means that in case of a rollback, the required artifact has to be built again, and needs to go through every environment to make sure it will function correctly.
In order to improve on the situation, we focused on the following aspects:
- Versioning system
- Customizable build server
- Everything as code
Versioning system
With a proper versioning system in place, you should be able to trace back your released artifacts to the commit that built it. In addition we introduced a second artifact repository, only containing software that is released (went through the complete pipeline). For versioning we l borrowed concepts from Trunk Based Development and semantic versioning, for storing artifacts we used a Nexus snapshot repository and a Nexus release repository.
Customizable build server
Business requirements regarding the build process can change over time. Therefore, we need a build server that is able to adapt to changes when needed. In this situation we ran Jenkins, primarily making use of the pipeline and multibranch plugin. These plugins (among others) enable the ‘everything as code’ approach.
Everything as code
I prefer code to be readable and modular. This simplifies code reviews and handovers (future proofing). It also ties in with having a customizable build process. We provisioned servers using Ansible playbooks, and configured Jenkins using Dockerfiles and groovy initialization scripts. Every application has its own code repository with Jenkinsfile that triggers a Jenkins job on every commit to trunk.
Plan
Below you’ll find the first iteration of our proposed versioning system and build process. In short:
- Automatic build and deployment to DEV server on commit to trunk. Snapshot artifact version number is a combination of build number and abbreviated commit hash.
- Manual trigger deploys artifact to TEST.
- In order to deploy to UAT / PROD, artifact needs to be released. This is done by creating a release branch from the commit. The build is triggered and moves the specified artifact to the release repository.
- Manual trigger deploys artifact to PROD.
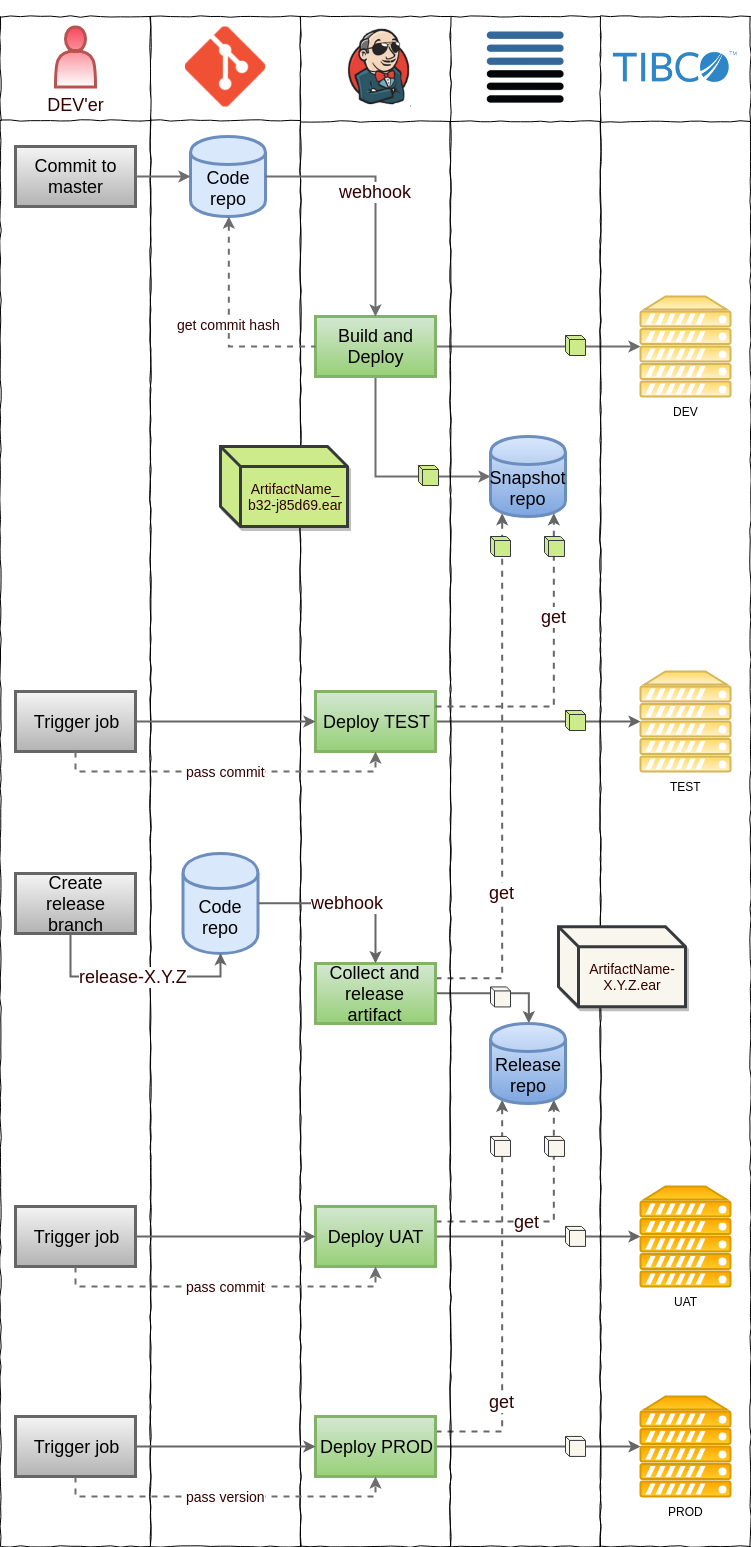
Proposed versioning system and deployment process.
Realization
We used a playbook to provision the server with Jenkins and Nexus and Docker to run Gitlab. Every Tibco application has its own repository on Gitlab with a generic Jenkinsfile. This file describes the process the application goes through (build, test, deploy). All application agnostic logic and global variables are abstracted to a shared library. This way, making a change in the process or configuration happens only once.
In order to build and deploy Tibco application with Jenkins, BW6 is installed on the server so the binaries can be used inside a script block. This is implemented by initializing a Tibco class in the pipeline from which we call the the build method.
// Jenkinsfile
@Library(‘jenkins-shared’) _
import com.devoteam.Tibco
def t = new Tibco(this)
…
script {
t.buildArtifact(
bwDesignPath,
propertiesFile,
workspaceDir,
appName,
pathToApplication
)
}
…
The class’ build method will take care of building the artifact:
// src/com/devoteam/Tibco.groovy
Class Tibco {
Tibco(steps){
super(steps)
}
Def buildArtifact(
String bwDesignPath,
String propertiesFile,
String workspaceDir,
String appName,
String pathToApplication
) {
sh “${bwDesignPath} --propFile ${propertiesFile} -data ${workspaceDir}
system:export -e ${appName} ${pathToApplication}”
}
After building the application, uploading it to a TEA server is also done with invoking the REST API with a shell command:
curl -XPOST -F "file=@${FILE}" "${bwAgentUrl}/bw/v1/domains/${bwDomain}/archives"
Before deploying to DEV, we push the artifact to Nexus. We pass it a version that easily traces the artifact back to the actual commit and build:
Script{ commitHash = “${env.GIT_COMMIT}”.substring(0, 8) Version = “b${env.BUILD_NUMBER}-${commitHash}” }
In the near future we will improve our build automation process by streamlining the Jenkinsfile and include automated testing using Postman.
Lessons learned
While building this pipeline we learned to keep things simple and modular. The first draft of our Jenkinsfile contained mixed groovy code and shell script to execute all steps in the pipeline. It worked, but it was a pain to maintain it for all Tibco applications. That lead us to the use of Jenkins shared libraries. Now, instead of defining logic in every Jenkinsfile for all applications, it is defined in one central place which makes it much easier to maintain.
Shared libraries also allowed us to split up logic in smaller chunks. Instead of having one large stage in our pipeline that interacts with the TEA server, we created a Tibco class with several smaller methods to do this.
This approach makes our codebase easier to maintain and enables us to add functionality faster than before.
If you have any questions or comments considering this blog-post, contact me via my contact details below.

Next Tibco CICD Blog-Post Coming Soon
A follow up blog-post will be published soon. This blog-post will dive deeper into this specific case and discuss new developments. Follow our LinkedIn and/or Twitter and stay tuned.
Devoteam: the #1 partner when it comes to Tibco BusinessWorks
Due to our background in Integration and DevOps, we are the #1 partner for well-known Dutch organizations when it comes to Tibco BusinessWorks. Curious to learn more? Read all of our success stories, use cases, and technical blog-posts.

