

How Garbage-In > Garbage-Out practice contributes to bad decision making?
We all heard about garbage in, garbage out. This is especially true if we consider data that we use for any elegant, well tested model or software. If we only focus on the quality of code and libraries when developing a solution and ignore the quality of the data used, then it should be no surprise that the output of the models / software will never be what we expect.
What is Data Quality?
Today dependency on data for many activities and processes is increasing rapidly. Considering also the hyper automation trends, the quality of data itself is growing in importance. According to the Global Data Management Community (DAMA), Data Quality consists in “planning, implementation and control of the activities that apply quality management techniques to data, in order to assure it is fit for consumption and meets the needs of data consumers.” Data quality management is a core component of the overall data management process.
Why Data Quality?
Organizations are running many Business Intelligence solutions for analytical and decision-making purposes. Reports generated are reliable only when the data quality is good. Data Quality is imperative to the success of any Business Intelligence solution. In today’s era, where the data is being ingested from multiple sources, the quality of the data might differ between sources. The basics to a successful business intelligence capability implementation is ensuring that only the highest quality data makes it to the repository destination used for reporting and dashboarding.
Why a Data Quality Framework?
A data quality validation solution must be in place, that will constantly measure the quality of data and act upon, applying automated correction preferably or at minimum report the quality issues found. Data management teams should use these inputs not only to fix the specific quality issue found, but also to design & implement processes to automate further the repeated occurrence of the similar data quality issue. Welcome to a Data Quality Framework.
Key must-have characteristics of a Data Quality Framework:
- Comprehensive capability to define and execute validation & healing rules against diverse data sets;
- Reliable scaling efficiency to support data quality monitoring and healing across multiple data domains with consistent performance;
- Outstanding logging capacity to store the results of the rules executions supporting audit needs but also for measuring effectiveness of the solution and also future analysis in improving the quality of the framework itself.
Data quality dimension
Every organization should have some means of measuring and monitoring data quality. Organizations should identify which data items are critical to its operations and measure them using the appropriate dimensions. This will help identify issues and plan for improvements. Dealing with Data quality is simply a perpetual process; measuring the quality of data regularly as data can change over time.
Data quality dimensions are measurement attributes of data, which are individually assessed, interpreted, and improved. Typically, the following six key dimensions are used.
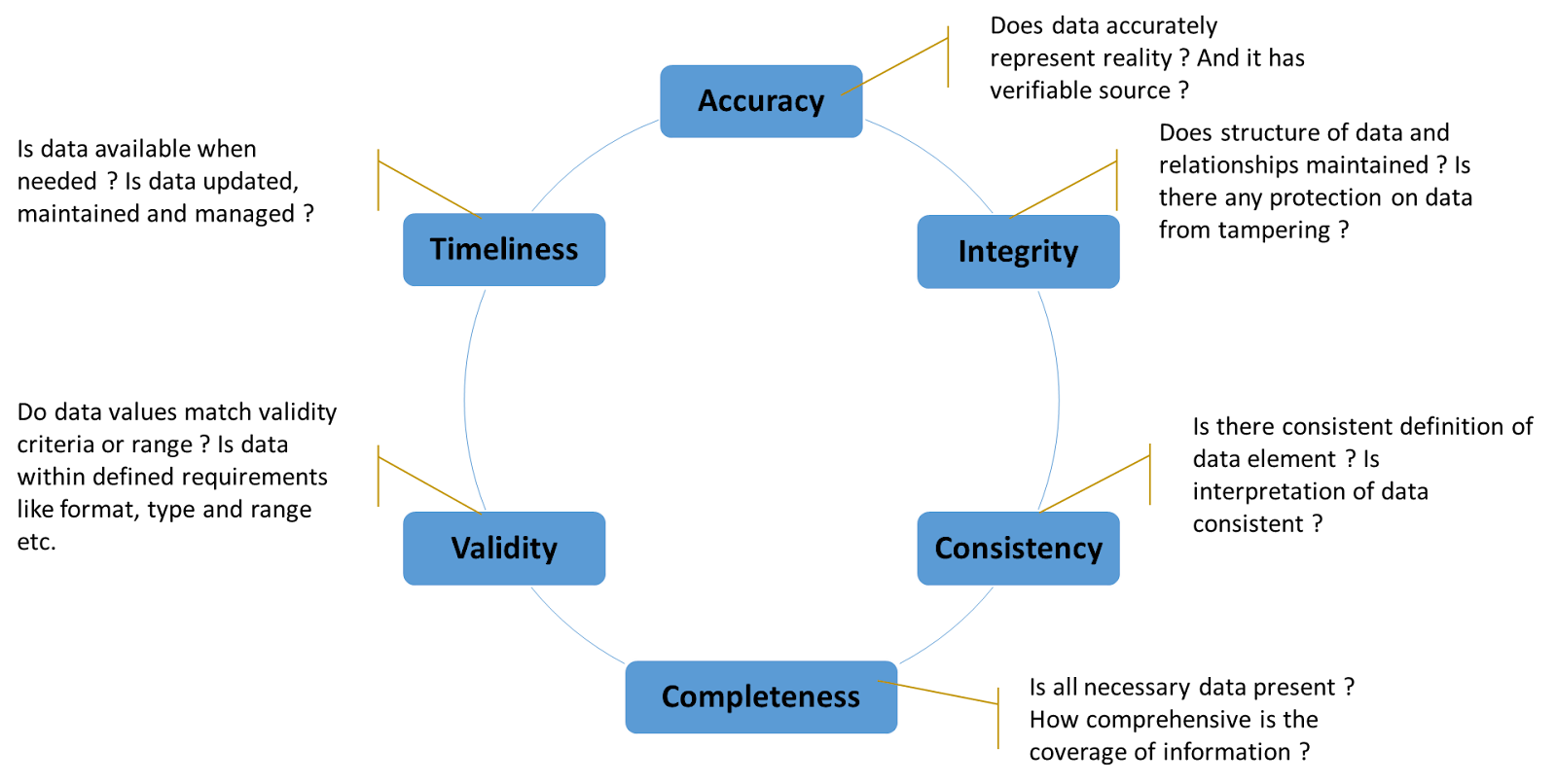
Many more dimensions are also available to represent distinctive attributes of data. Based on the business context you can choose appropriate dimensions. Following links are helpful to get more details on data dimensions:
- http://www.dama-nl.org/wp-content/uploads/2020/09/DDQ-Dimensions-of-Data-Quality-Research-Paper-version-1.2-d.d.-3-Sept-2020.pdf
- http://www.dama-nl.org/wp-content/uploads/2020/11/How-to-Select-the-Right-Dimensions-of-Data-Quality-v1.1-d.d.-14-Nov-2020.pdf
Addressing Data Quality natively in Azure
Azure allows for a simple yet powerful way to address data quality issues while defining a data flow.
The steps in this sample data flow are depicted below:
- Define source dataset using source parameters and linked services
- Using schema modifier Select option filter columns on which you want to apply data quality rules
- Using Derived Column implement rule using expression language against the column values
- To produce aggregated result of overall data quality use Surrogate key and Aggregate schema modifier of data flow
- Use destination Sink to store the data quality result at your desired location using sink parameters and linked services.

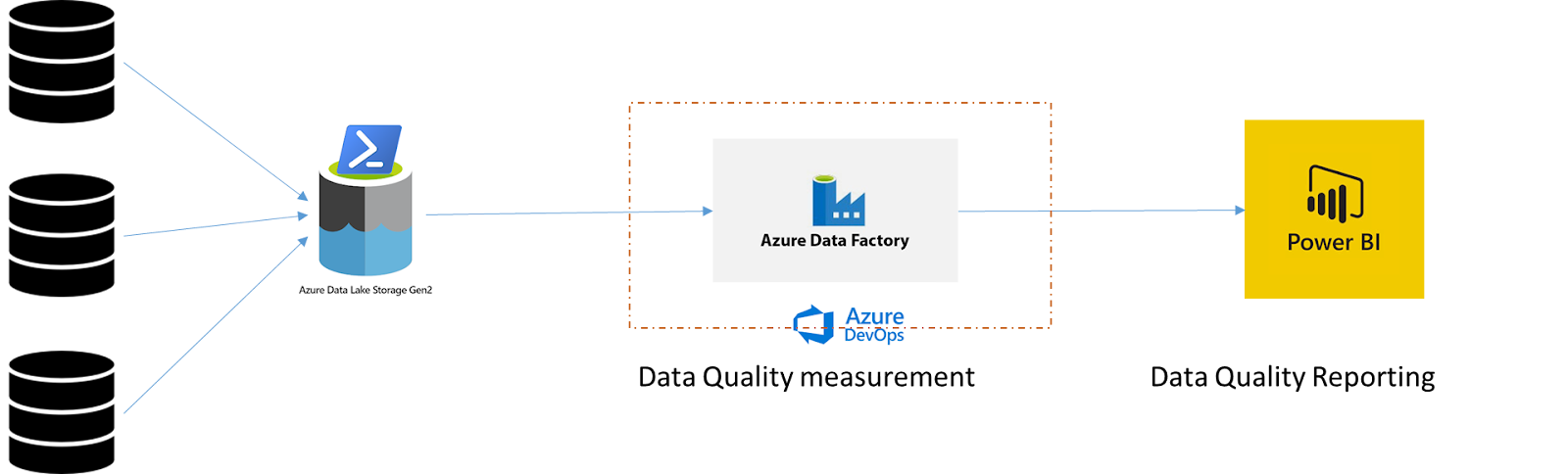
Using dataflow within Azure data factory we can implement data quality rule measurement and use Power BI for reporting those.
Data quality framework can be divided into two parts: Measurement and Reporting. These should be decoupled so developers can choose multiple ways of measuring data quality based on technologies used for ingestion or choice of developers and keep reporting at organization level standardize. For example Data quality measurement can be performed using ADF, Databricks, custom apps etc. based on need/choice while keeping reporting consistent using Power BI by accepting a fixed set of fields to generate reports.
Conclusion
Any organization that has the ambition to be an “Insights-Driven” organization must have a trusted Data Quality framework in place that will eliminate the Garbage-In > Garbage-Out constellation. The alternatives can be just too harmful. Devoteam M Cloud is a Microsoft Managed Partner with an established track record in bringing organizations to their next level of data & insights journey. Reach out to us for adept advice about Data Quality or any other data & insights related topic.

