
In late 2018, the KNMI (Royal Netherlands Meteorological Institute) embarked on its most ambitious project of recent times. Over the past three years, it executed a remarkable digital transformation of its enterprise architecture and IT processes. At the core of this transformation is the migration of KNMI’s IT systems to the Cloud. A move from an aging on-premise data center, to a modern, well-managed Cloud platform. Devoteam has been a supplier of KNMI, and we have worked with KNMI along this journey. Today, KNMI effectively has both feet in the Cloud and stands poised to harness the benefits of this transformation. Therefore, it is only a fitting moment now to write about this large-scale Cloud migration. This case study is a first-person report that will dive into the anatomy of the project.
KNMI and its changing context
KNMI is probably one of the first data-driven organizations in the Netherlands. Change has been a constant factor in the 166 years of KNMI’s existence since its area of business lies in the geophysical environment, and this will be no different in the years ahead. Apart from the public, several important Dutch companies such as Rijkswaterstaat and Schiphol rely heavily on KNMI data. KNMI’s mission, as laid down in 2014, remains the focal point of its work:
KNMI advises and warns society about risks associated with weather, climate, or seismology that need to be mitigated to limit societal damage and injuries. It uses its top-quality knowledge, technology, extensive monitoring, and model network to offer products and services that contribute to the safety, accessibility, environmental quality, and prosperity of the Netherlands.
To help with its mission in the coming times, KNMI needed to expand its capacity to handle ever larger quantities of data, the ability to adapt and implement changes with ease, and to be able to test and deploy IT systems and models with increased efficiency.
Why move to the Cloud?
In the KNMI context, going to the public Cloud was an obvious choice. Firstly, a Cloud provider makes large amounts of computing, storage, and other resources available on demand. This would support the growing number of services that KNMI has been building over the past 10 years. Research teams can make use of fully managed research environments. By leaving the development and maintenance of these services to a cloud provider, developers can focus on core tasks. Secondly, the Cloud provides these services at scale and is often more robust, cheaper, and more secure than when we would build on our own. Lastly, a move to the Cloud offers the opportunity to optimize and standardize, create fully reproducible environments, increase security and implement state-of-the-art CI/CD mechanisms, and above all, get a grip on costs.
In late 2018 a proof-of-concept environment with AWS (Amazon Web Services) Cloud was developed. This was a small sandbox environment, but it demonstrated the capabilities of the Cloud very clearly. The Cloud Migration project was born, thus setting in motion the creation of the central AWS Cloud platform at KNMI.
Application migration approaches
A large-scale transformation project of this nature poses tricky and unique challenges. We had to build the Cloud platform, but that wasn’t the goal. The bigger, overarching goal was to migrate many applications to the Cloud. We were staring at an initial list of upwards of 150 applications. The key metric to live by was the “Number of applications migrated”. But how do we pick the first application to migrate? The success of the front-runners could determine the success of the project. The complexity of the application would determine the speed of migration, but also what kind of “unknown unknowns” we’d encounter in the new Cloud environment. The approach was to start with a set of “simple” applications, together with at least a couple of “complex” ones. By doing this, we are making the first quick wins, but also building out the platform to support the more complicated scenarios.
A multitude of applications that consisted of a web frontend backed by a database fell in the “simple” category. The standard approach adopted for these was a form of re-architecting by the containerize-and-deploy method, leveraging the Amazon ECS (Elastic Container Services) service, backed by an AWS-provided database such as Aurora PostgreSQL. Standards for code, CI/CD, and Git workflows were easily developed to serve as templates.
Lift and shift
As for the first more complicated workload, we created a design spanning several core AWS services including EC2 instances, AWS Lambda, and Application Load Balancers. This had to be a partial lift-and-shift due to complexities with internal application dependencies as well as external vendor dependencies. Translation of design to code to deployment would go hand-in-hand with developing the platform building blocks.
The Cloud Platform team had to have both a short-term and long-term vision for the migration. A key challenge was to get the rest of the organization on board, not just with the hard technical skills they needed to learn, but also the mindset required for Cloud. The team takes on a key role focused on education and coaching.
Organizing the Platform team
In the first months, a lot of focus was on building the platform and application migration. At the end of the first year, we had no fewer than 10 applications on production. This meant someone had to ensure the optimal operation of these applications and the underlying platform. After a really short period of experimentation with an Operations team, it became apparent that we simply could not have a separate Ops team. “Handovers” are the antithesis of DevOps. A cross-functional team that did everything from building the platform, assisting application teams with migration, and operating the platform was the only way forward.
We went full DevOps
Work was planned and managed following Scrum by the book. This meant two-week sprints, daily scrums, sprint plannings, ad-hoc refinements, and retrospectives. Through collective effort, we could make Scrum work for us. If something felt like a chore, we inspected and adapted. In fact, it became almost impossible to imagine having to manage work differently. The most important session was the bi-weekly retrospective where we would engage in transparent self-inspection, and systematically adopt our way of working. A “Way of working” document on Confluence acts as a code of conduct for things agreed upon as a team. Having the way of working codified in this way is not only great for team members, but for a rookie in the team as well. The retrospectives were the vehicle to adapt and evolve this way of working documents.
To strategize even better, we introduced Quarterly plans in the form of OKRs (Objective and Key Results). OKRs are a collaborative goal-setting framework made popular by Google’s SRE movement. OKRs quickly became popular with more teams, and Quarterly planning meetings with the whole department have become a standard.
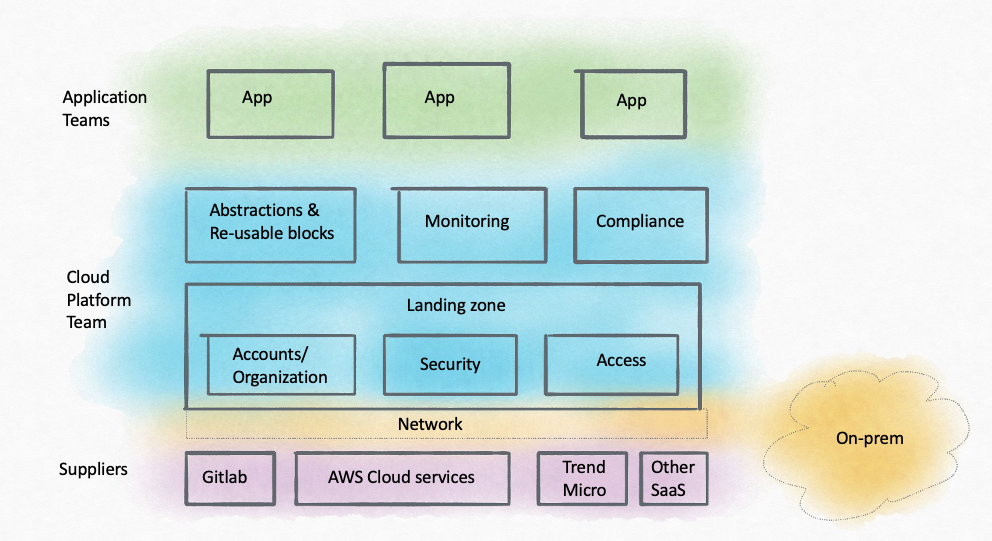
Architectural principles and its evolution
The migration was guided by several architectural principles, of which I’d fancifully name the key ones, the three S’s:
Simplicity
Any solution to a problem had to be simple and maintainable. This means eliminating unnecessary dependencies at the application as well as platform level. When there was a choice to be made for a service or tooling to be used for a solution, the approach was almost always to pick the equivalent AWS service if it existed and was of sufficient quality.
Standardization
Several building blocks were developed which could be reused by several application teams without having to repeat the implementation. This covered most core services in the areas of monitoring, access, security, and CI/CD tooling. The AWS Well-Architected Framework provides a good guideline for building systems on the Cloud. We decided to use the framework for all the building blocks, addressing the key aspects of the system such as Security, Reliability, Operational Excellence, and Cost optimization. All our design was guided by the framework, and we attempted to enforce it to a certain extent, using tooling such as AWS ConfigRules.
Self-service
Self-service enables DevOps teams. And Git is where it begins. Everything from application to infrastructure has to be in code and pushed to a Git repository. Standard AWS CloudFormation custom resources and nested stacks were created as building blocks for infrastructure-as-code. GitLab-CI pipelines with reusable job templates were also created. A Git-first approach was promoted organization-wide. Several service requests to the Cloud platform team were automated so that they would simply be a Git merge request to be raised by the application teams.
Almost none of the architectural choices made are permanent, but they can be contested and reviewed. The Tech Tuesdays are a unique invention, an organic forum where the platform team members, and for that matter, anyone with interest in the Cloud platform can participate and bring topics to the table. The participation of enterprise architects in these meetings fuels decision-making and sooner course corrections. Each topic would be picked up and discussed within an agreed time box, usually of 10 minutes or multiples thereof, and action points created with an action owner assigned. Although named “Tech Tuesdays”, the topics discussed may fall under any category involved with the Cloud platform, including processes as well.
Centralized support and response
A central platform team supporting multiple development teams became a focal point for change and innovation. The support to application teams is delivered in various forms such as planned migration help, incident resolution, and consultancy.
Support would be provided not only via the standard ticketing system but also through an informal question on Slack. An external-facing support channel was created on Slack for this sole purpose, next to the team-private channel. The channel is home to too much technical banter. Questions may be answered by anyone on the channel, another avenue to foster knowledge sharing. Repetitive questions were monitored, picked up by the team, and automated when the value was high enough. It is not easy to provide a sufficiently timely support response while working on a packed backlog. This kind of approach calls for certain pro-activeness among team members.
While ad-hoc and proactive support is great, it can only go so far. A maturing Cloud platform with multiple applications on production calls for more structural support. Assignment of designated support staff on standby both during the day and night needs to be arranged. An alerting system that is reliable, data-driven, and works for you is essential for modern Ops. A Lambda function triggered by a CloudWatch metric threshold that would send a message to the team Slack channel was the first step in this direction. As we built a robust monitoring system based on AWS ElasticSearch (now OpenSearch) we moved towards Grafana as a standard monitoring tool, part of the monitoring building block reused by all teams. For teams requiring advanced alerting, we adopted OpsGenie. A modern alerting tool is essential for reliable incident response.

An agent of change
Apart from organizing workshops, the Cloud Platform team also brought several innovative ideas to the table. A bi-weekly Knowledge sharing session was organized covering topics related to the Cloud platform but also application-specific technologies. Documentation is a major driver in spreading knowledge, and we decided not to do documentation as an afterthought. For any given topic, wiki documentation would be created in the form of How-to pages and/or explanatory articles. The How-to page is a brief and numbered step-by-step procedure to accomplish something. The explanatory articles would provide more contextual information behind a setup or solution. Over the course of 2 years, we had built up a set of articles catering to the entire gamut of services. Providing support would often entail simply pointing to the relevant How-to page.
Apart from documentation and knowledge sessions, the Cloud platform brought several industries’ best practices into the organization. Doing blameless postmortems of incidents, conducting game day scenarios, and using the OKR (Objectives and Key Results) methodology to strategize, are a few to name. Leading by doing and showing what you do has been a very successful approach.
Ready for the future
By the end of 2021, the Cloud Platform team had reached “peak migration maturity”, having a total of 158 applications either migrated to AWS or phased out. With the end of the IT migration project, KNMI has built a robust Cloud infrastructure that is ready for workloads of the future.
In the coming years, the KNMI Cloud platform will host and support, among others, a modern multi-hazard Early Warning Center (EWC), i.e., a national warning system, producing high-quality warnings, scenarios, and advice.
Related resources
Below, we have gathered a list of relevant content and resources for you that touch upon the topics discussed in this case study.
- E-book: Accelerating Digital Innovation with Cloud, by IDC & Devoteam
- E-book: 5(+1) ways to get in control of your cloud IT costs, by Devoteam
- E-book: The Future of DevOps, by Devoteam
- Service: Unlock agility & drive growth with Distributed Cloud
- Service: Speed up innovation with DevOps
- Service: Empower your business with the AWS enterprise platform

