

Published on: 22-06-2021
The organization I am working with is building a consumption layer for Business Intelligence. For that purpose, we researched on different Data warehousing solutions including Azure Synapse and Databricks SQL.
Databricks SQL
Databricks SQL, which has recently gone in public preview, is unique in the sense that one can perform Business Intelligence related Data Analysis directly on a Data Lake with it. It integrates with tools like Power BI and Tableau and provides a great user interface where you can directly write SQL queries for querying tables that exist in the Delta Lake.
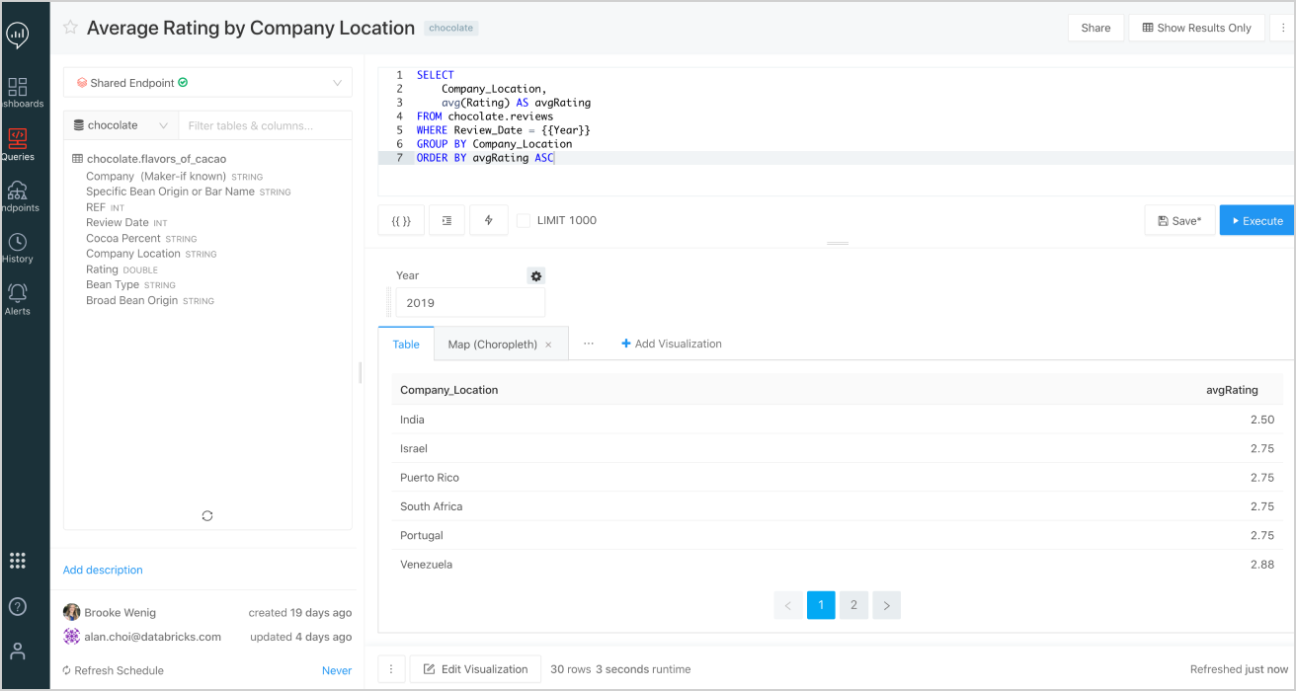
Note that nowadays Azure Synapse also allows querying data in the Delta Lake directly using Server less pools, but that feature is still in preview.
We put Databricks SQL to the test, with two test queries to create tables. Both queries use the same three tables as sources. These tables contain 205 million, 665 million and 5 million rows respectively. The queries are big and involve join, aggregation and window operations. Following are the results for different cluster sizes for these two queries (Transactions and TransLines).
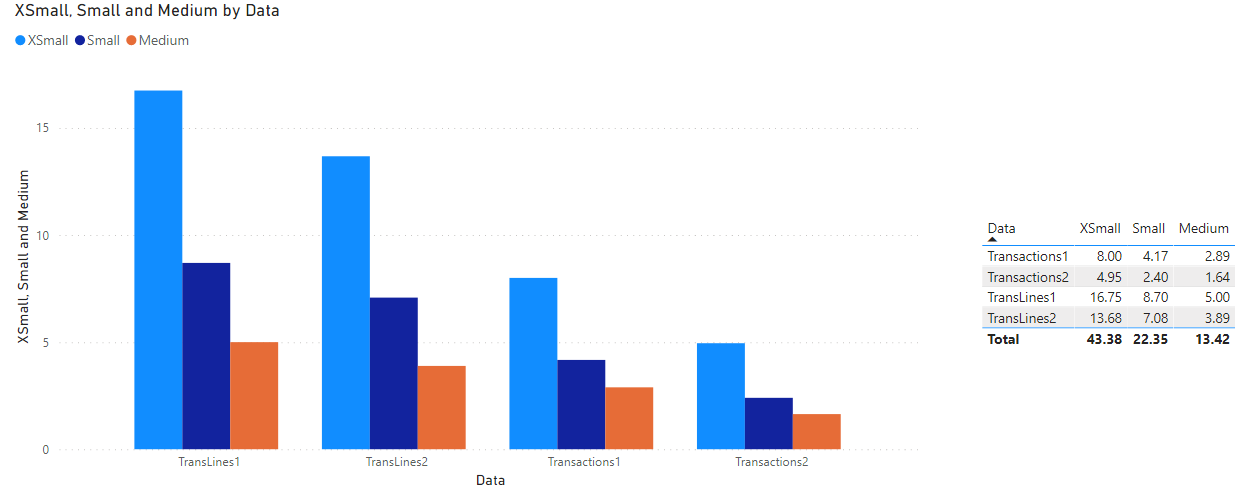
Here TransLines is more compute/data intense because while Transactions only involves left joins besides aggregation, TransLines also has a full outer join and a window operation besides aggregations. We tested the performance in two ways. First by running the query after spinning up a cluster and second when having the source tables cached. Because what happens is that after you use a source table once, it is cached. I am not sure what exactly happens if the source table is modified, but I can imagine that Databricks SQL must have a way of only updating the modified partitions. In our case, the data is partitioned by days. From the above diagram, we can see that the performance scales very well and caching really helps.
We noticed that caching significantly improves the performance of direct query in PowerBI. We tested that with smaller aggregated tables. This is because after the initial load, any interaction with a report/dashboard gets the data from the cache.
We also compared the performance of Databricks SQL with Synapse as shown below. For Databricks SQL, we used a Medium cluster size, whereas for Azure Synapse, we used DW1000c. The cost for both is similar with DW1000c’s being slightly higher. The results are following.
| Query | Execution Time (mins) |
| Transactions Synapse (Round Robin distribution) | 3.73 |
| Transactions Synapse (Hash distribution) | 2.13 |
| Transactions Databricks SQL (Not cached) | 2.89 |
| Transactions Databricks SQL (Cached) | 1.64 |
| TransLines Synapse (Round Robin distribution) | Timed out (not completed within 30 minutes) |
| TransLines Synapse (Hash distribution) | 9.03 |
| TransLines Databricks SQL (Not cached) | 5 |
| TransLines Databricks SQL (Cached) | 3.89 |
Conclusion
We can see that Databricks SQL outperforms Azure Synapse in cost. However, Databricks SQL is not yet as polished as Azure Synapse and is still in public preview.

