
Databricks stands as a pioneering force in the ever-evolving landscape of data technology, while Microsoft Fabric emerges as a sensation, promising innovative solutions. In this exploration, we delve into the synergies between these two powerhouses — Azure Databricks and Microsoft Fabric. The aim is to decipher how the integration of these cutting-edge platforms within the Medallion architecture can collectively address intricate data challenges. Join me on this journey as we unlock the potential of combining Databricks and Fabric to create a robust and comprehensive solution for navigating the complexities of modern data problems. Let’s harness the strengths of each, fusing innovation and practicality to pave the way for a data-centric future.
In this blog post, I will be focusing more on how to establish a connection between Azure Databricks and Microsoft Fabric together with the process of ingesting some sample data from ADLS sources into the Fabric lakehouse and performing data processing using Azure Databricks.
Medallion architecture with Microsoft Fabric and Azure Databricks
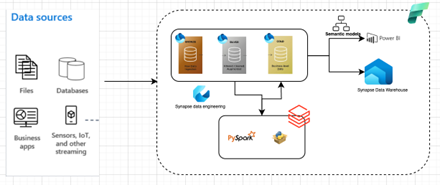
High level design diagram
The Medallion Lakehouse Architecture, commonly known as Medallion Architecture, is a recommended design pattern for logically organising data in a lakehouse, especially in the context of Fabric. This architecture consists of three distinct layers or zones, each representing a different level of data quality — bronze (raw), silver (validated), and gold (enriched). The multi-layered approach aims to establish a single source of truth for enterprise data products. Importantly, the Medallion Architecture ensures the ACID properties (Atomicity, Consistency, Isolation, and Durability) as data progresses through these layers, starting from raw data and undergoing validations and transformations for optimised analytics.
The high-level design diagram illustrates where we can position Azure Databricks alongside Fabric for the implementation of the Medallion architecture. There are two ways to connect Microsoft Fabric OneLake from Azure Databricks:
- Connect the Fabric lakehouse using the Azure Data Lake Storage (ADLS) credential passthrough method. You can find a step-by-step approach in the Microsoft documentation here.
- Connect the Fabric lakehouse with a service principal.
For example, if your Azure Databricks and Microsoft Fabric are on different tenants and you need to establish a connection between these resources. In this scenario service principal approach(option 2) will be the solution.
Step by step approach to connect the Fabric lakehouse with a service principal
- Create an Azure service principal in the Fabric tenant. Click here for the documentation.
- Give the contributor access to the newly created service principal in the Fabric workspace.
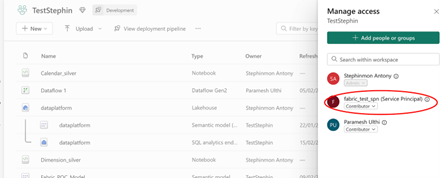
Manage access in the Fabric Workspace
- Keep the service principal secret in the Azure keyvault.
- Integrate the keyvault with Azure databricks using create secret scope. Click here for the documentation.
- Mount the Fabric Lakehouse with Azure Databricks using a similar approach to how we mount ADLS with Azure Databricks.
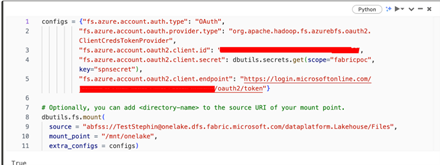
Databricks mounting script
- Now, you will be able to read and write data into the Fabric Lakehouse (OneLake) from Azure Databricks.
How to execute Azure Databricks notebooks from Microsoft Fabric
The Data Pipeline feature in Synapse Data Engineering is used for the data pipeline orchestration. It’s similar to Azure Data Factory; Azure Databricks activity can be used to execute Databricks notebooks from Microsoft Fabric. Click here for the detailed documentation.
Example: Data Ingestion and Data Processing
Microsoft Fabric provides a shortcut feature for directly ingesting data into the lakehouse from ADLS. To kick things off, our initial step involves mounting the source and target locations in the Databricks workspace. Take a look at the sample notebook below, which illustrates how to ingest data from the raw (ADLS) layer to the Bronze (Fabric Lakehouse) layer.
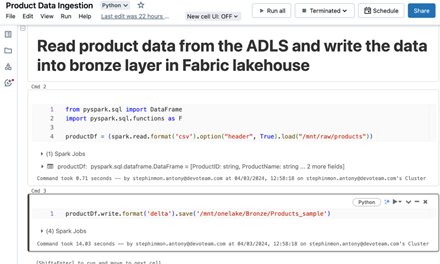
Sample Data Ingestion notebook
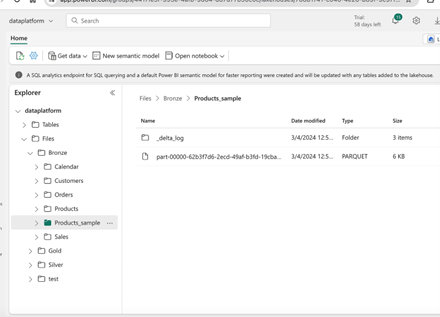
Fabric lakehouse
I am not planning to illustrate all the multihop layer processing here but rather focus on a sample data processing scenario. For that purpose, I’ve created an example notebook for creating a gold table with data aggregations. I have also orchestrated the data pipeline in the Fabric workspace. Please refer to the screenshots of the notebook and data pipeline provided below.
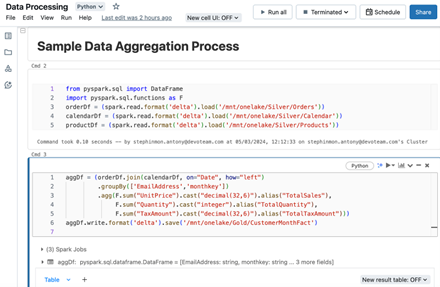
Data processing notebook
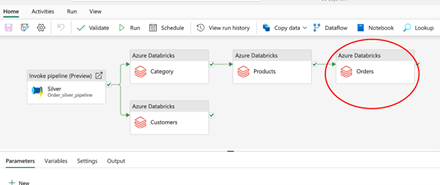
Sample Data pipeline
In the above pipeline, I’ve highlighted the notebook activity responsible for creating the gold tables.
Conclusion
Integrating Azure Databricks with Fabric for the Medallion architecture will empower the system even further. Azure Databricks is an integral part of a data-driven organisation. This approach allows the data platform to leverage the benefits of both tools.Note : We are delighted to assist you in solving your data problems, or if your organisation is keen to explore the capabilities of Microsoft Fabric for addressing business challenges.

