Delta Lake 0.3.0 was released on August 1st, 2019, bringing delete, update and merge API support and many other features on top of Apache Spark. Before going into what the latest version brings, let’s see what Delta Lake is.
What is Delta Lake?
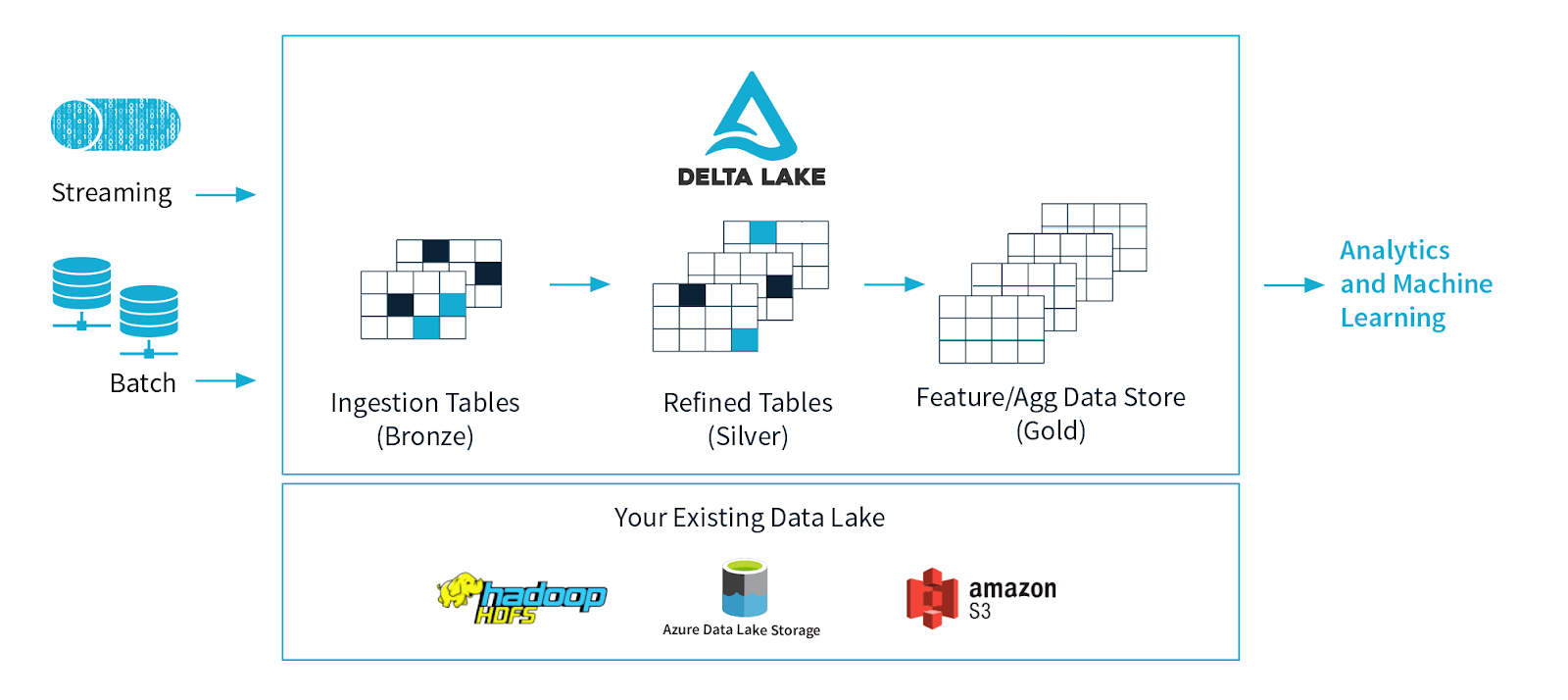
According to its own web site, “Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads”.
Delta Lake began as an internal Databricks project, called Databricks Delta, that started to be open-sourced in April 2019 under the Apache License 2.0. Delta Lake was announced at the Spark + AI Summit 2019 in San Francisco as the “First unified data management system that delivers the scale of a data lake, reliability, and performance of a data warehouse and the low latency of streaming.”
What are the Delta Lake key features?
Delta Lake claims to provide the following key features:
- ACID Transactions
- Updates and Deletes
- Schema Enforcement
- Schema Evolution
- Unified Batch and Streaming Source and Sink
- Scalable Metadata Handling
- Time Travel (data versioning)
- Open Format
- Audit History
- 100% Compatible with Apache Spark API
What does release 0.3.0 bring?
The release notes of version 0.3.0 highlight the following main features:
- Scala/Java APIs for DML commands – The data in Delta Lake tables can be modified using programmatic APIs for Delete, Update and Merge (upsert).
- Scala/Java APIs for query commit history – The table’s commit history can be queried to see what operations modified the table.
- Scala/Java APIs for vacuuming old files – Keeping all versions of a table forever can be prohibitively expensive. Stale snapshots (as well as other uncommitted files from aborted transactions) can be garbage collected by vacuuming the table.
Known limitations
Something that we need to keep in mind regarding Delta Lake 0.3.0, is that it is still an early release and not yet widely adopted. Also, at the moment there is no release plan published, so there is little visibility in the future of the Delta Lake project. With this caution notice, Data Lake promises to fill in the great demand of the Apache Spark users for transaction support.
Some known limitations of the current Delta Lake version are the lack of migration tools from existing tables to the new Delta Lake format and the lack of multi-table transactions or explicit transaction definition using statements like begin, commit or rollback.
Dealing with records that are not conforming to the expected schema is not implemented yet, but there is a feature called expectations, which defines the criteria for accepting data, that might come from the Databricks Delta to Delta Lake in the near future.
The API is currently available only in Scala and Java, and not in Python or SQL, but the new language support should be expected in the next releases.
Conclusions
Delta Lake was just released in the open-source community this year, so we should keep an eye on the evolution of this project, considering the support and experience of Databricks, who is the main project sponsor.
References
Databricks Delta: A Unified Management System for Real-time Big Data

