

Have you ever spent hours testing and checking data, have it delivered to your stakeholders, only to find them pointing out that another unrelated field is now showing incorrect data? If so, you’re not alone. Tracking down the root cause of data issues can be a tedious and time-consuming process, requiring you to traverse through multiple scripts and data sources. This is where data lineage can be incorporated. By tracing the movement of data from its source to its destination, data lineage provides a visual understanding of how data has been transformed and manipulated. In this blog, the concept of data lineage using Databricks will be explored to show how it can help in pinpointing data issues.
What is Data Lineage?
Data lineage is a critical aspect of data management that tracks the journey of data and aims to showcase the flow from the source location. Such as files, APIs or Databases, all the way to the end location, be it a report or application. Lineage includes all the transformations that are applied on the data itself, or the combination with other sources to create new fields. This aspect of data managament aims to provide a visual overview of the data journey, that will aid in tracing the root cause of data issues, enhancing quality and trust in the data pipeline (1).
The Databricks Lakehouse platform provides data lineage solutions at field level. This means that users can track the lineage of individual fields within a dataset, rather than just at the table level. This detailed view of lineage provides a better understanding of how data has been transformed, and can help to identify issues that might be missed at a higher level. In addition to providing a visual overview of data lineage, Databricks also allows users to manage lineage data in a centralised and structured manner as it requires the use of Unity Catalog. This ensures that lineage data is always up-to-date and accurate, making it easier to collaborate and share insights across teams (2).
Data Lineage with Unity Catalog
To make use of Data Lineage, the Databricks Workspace must have Unity Catalog enabled and the account has to be on the Premium Pricing Tier (3). The tables that are going to be tracked for lineage must be registered in Unity Catalog, a centralised and managed location for all data assets.
Basic tables were created to represent different layers in a simple Data Warehouse, the data and the code was taken by cloning the Github Repository (4), in section 8.1.2 under Delta Live Tables. A bronze layer including the tables customers and sales_orders_raw was created by loading raw data into tables from source files located on Databricks File System (DBFS). The silvery layer table sales_orders_cleaned uses the first layer as source and involves the cleaning and transformation of data. In the last layer, the gold layer, aggregation of data is done and loaded in dim_sales_order and fact_sales_order, to display it in a summarised manner that can be reported.
To view the most awaited Lineage Graph, go to Data to view the Data Explorer, choose the catalog where the tables were created, choose one of the table and click on See Lineage Graph:
Viewing the Lineage Graph on Databricks
The Lineage Graph provides an interactive General User Interface (GUI). Each individual table is represented by a box that includes line links coming from each field, displaying both upstream and downstream dependencies, together with the data type of the field. Having this visualisation allows users to follow the data stream in each layer, and understand the interdependencies between tables and fields. This provides useful information for composite fields such as order_key which is made up from customer_id and order_datetime. It is able to determine the links for array data types, as shown below by the fields that were created by exploding the array field ordered_products in the table sales_orders_cleaned.
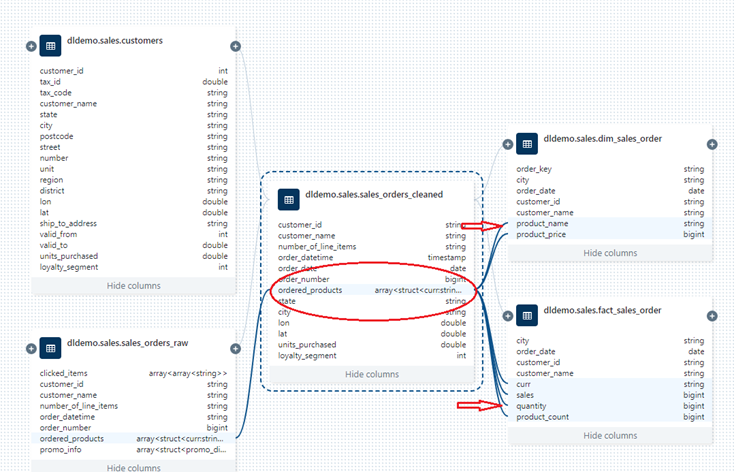
The downstream fields and links coming from the array field ordered_products in the silver layer
Clicking on the sales_order_cleaned provides a window containing table and notebook level lineage. In this scenario, notebook level lineage was shown with the same notebook throughout, as the code for both tables was found in the same one.
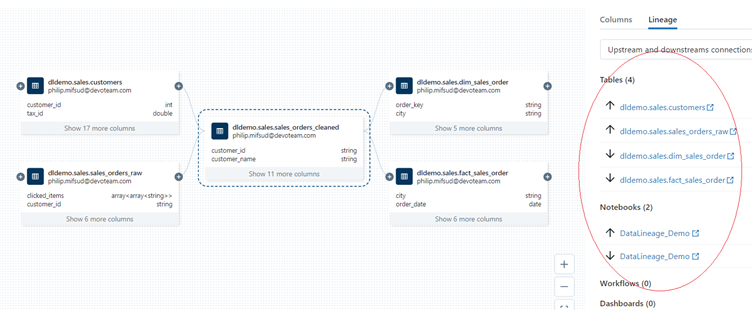
Clicking on the sales_orders_cleaned box provides table and notebook lineage
Although data lineage on Databricks is a useful feature it does not come without its imperfections. It is not able to indicate the source from where the bronze layer tables were created, which are JSON files stored on DBFS. Also, clicking on any field will only show you one upstream and downstream hop, as displayed on the image below on the gold layer table. The user has to follow each link upstream and this can become overwhelming to follow through a large number of tables and columns.
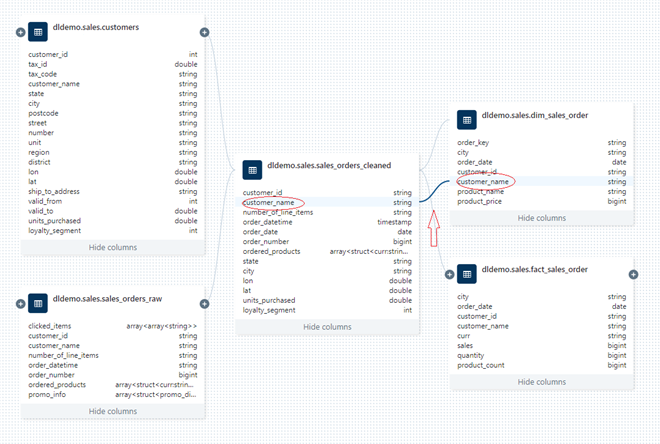
Clicking on customer_name from dim_sales_order showing the upstream hop
If data is written directly to files in cloud storage, lineage information is not captured, even if the table is defined at the same storage location.
This means that the process of writing data to cloud storage using a command such as spark.write.save(“s3://mybucket/mytable/”) will not result in the capture of lineage information.
Unity Lineage API
With the Databricks API, developers are able to integrate lineage data into their custom applications and workflows, which helps to improve the overall effectiveness and efficiency of data management activities. It provides developers with a flexible means of accessing lineage data directly. Developers can directly send requests to the Unity Catalog Lineage application and retrieve data lineage information in JSON format, by passing through a Command Line Interface (CLI) command (3).
The following section will show a basic use of the Databricks API for data lineage. Note, this should by no means be used for a production environment, it was only done for testing purposes.
- Start by generating a Databricks Personal Access Token (PAT).
- Go to user settings and under the section access settings press Generate new token, save the token string in a secure location.
- Install and configure the Databricks API on a Notebook temporary for testing.
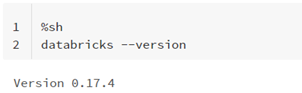
- Run the following shell command.
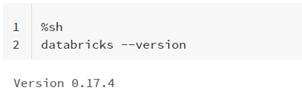
- Check that databricks CLI version is higher than 0.17:
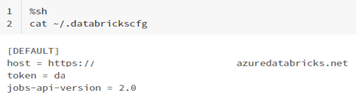
- The token was saved in a text file and the credentials for cli authentication were configured by using the command databricks configure. The token file and the Databricks Workspace url were passed as parameters:

- Check that the Databricks config file has been updated with the correct credentials:
To obtain the upstream and downstream lineage for the field customer_id found in the table sales_orders_cleaned, it was done as below:
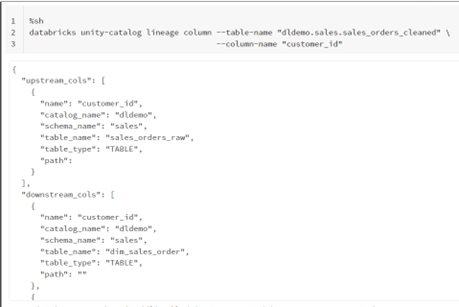
Data lineage API response for the customer_id column in the Silver Layer table
Benefits of Data Lineage
The Data Lineage on field level with Unity Catalog is a relatively new feature on Databricks which is available for no extra costs on Premium accounts. Currently, the automated data lineage is a good feature to use even at enterprise level with a large set of tables, as it provides a better understanding of the data flow with its interface. It benefits both engineers and business users, increasing collaboration and knowledge of their data flow. The ability to track lineage reduces the time spent in handling data quality issues, improving overall operational efficiency, by that organisational trust in its data which leads to more informed decisions.

