
Moderne IT-paradigma’s: decentralisatie versus centralisatie
Er lijkt een conflict te bestaan tussen de ontwerpfilosofieën van twee van de moderne IT-paradigma’s. Enerzijds is er het idee van microservice-architectuur. Het idee dat systemen in plaats van monolithisch te zijn, moeten bestaan uit onafhankelijke maar onderling verbonden onderdelen. Door deze onderdelen, of microservices, hun eigen infrastructuur en databases te geven, vergroot je de modulariteit, schaalbaarheid en vereenvoudig je de ontwikkeling en onderhoudbaarheid.
Aan de andere kant hangt het moderne data paradigma af van centralisatie. Om analyses en ad-hoc query’s mogelijk te maken, moeten gegevens uit het systeem worden verzameld en opgeslagen in een centrale gegevens repository, zoals een datawarehouse of een data lake.
Het ene paradigma wil dus centraliseren, het andere decentraliseren. Hoe kunnen deze twee worden gecombineerd?
Spanningen tussen de twee paradigma’s: hoe komt dat?
Als er maar één bron-database is, is het eenvoudig om regelmatig gegevens uit de transactiedatabase te lezen en op te slaan in het datawarehouse, zodat je hiermee rapporten kunt maken. Hoe meer van deze bron-databases er zijn, hoe ingewikkelder dit proces wordt.
Het is niet altijd de beste aanpak om de oplossing voor één database toe te passen op al je microservice-databases. In een monolithische database kunt je er gerust van uitgaan dat het database ontwerp relatief consistent is. Aangezien veel onderdelen van het systeem allemaal afhankelijk zijn van dezelfde database, zal het aanbrengen van grote wijzigingen in het database ontwerp grote gevolgen hebben voor het systeem, en zal dit bijna niet onverwachts gebeuren.
In een microservice-architectuur zijn de microservices ontworpen om zichzelf te besturen en alle gegevens te hebben die ze nodig hebben. Een microservice-database heeft maar één doel: het faciliteren van de microservice, en moet daarom op elk moment gewijzigd kunnen worden om beter aan te sluiten bij de behoeften van de microservice. Daarom kun je niet dezelfde aanname maken over een stabiel databaseontwerp zoals je dat wel kunt in een monolithisch systeem.
Omdat het formaat en de inhoud van de gegevens op elk moment kunnen veranderen, is het niet altijd voldoende om gegevens uit je databases te lezen en door te sturen naar je datawarehouse. In plaats daarvan heb je een manier nodig om up-to-date te blijven met de gegevens van elke microservice, zonder hiervoor direct de microservice databases te gebruiken. Maar hoe?
Oplossingen in Azure: Gebruik een berichtensysteem
Het probleem van datawarehousing in een microservice-architectuur kan worden opgelost door het gebruik van een berichtensysteem. We kunnen Change Data Capture (CDC) gebruiken in de microservice databases en de gewijzigde gegevens schrijven naar een specifiek onderwerp van een berichtenservice. Een pipeline kan dit bericht vervolgens eenvoudig oppikken, verwerken en de gewijzigde gegevens opslaan in het datawarehouse.
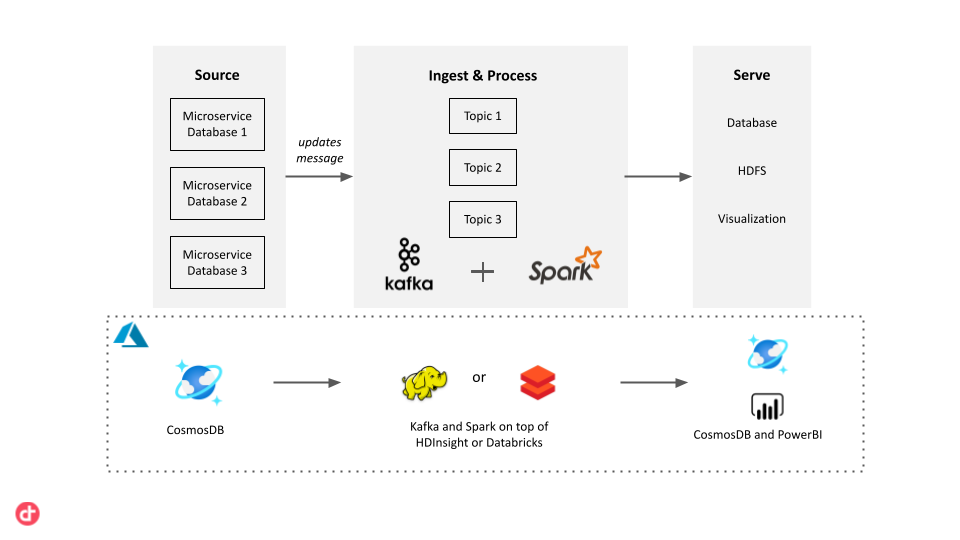
Azure biedt verschillende opties voor back-end databases, die front-end-applicaties in meerdere verschillende data-formaten kunnen ondersteunen, afhankelijk van de behoeften van een applicatie. Als we bijvoorbeeld een web-app met document databases hebben, kan deze gemigreerd worden naar de MongoDB-API van CosmosDB.
Open Source & SaaS-oplossingen
We kunnen Apache Kafka gebruiken voor de berichten component. Elke keer dat een microservice een wijziging aanbrengt in de CosmosDB-database, schrijft deze een bericht naar een Kafka-onderwerp. Om deze berichten te verwerken, kunnen we Spark Streaming gebruiken. Dit integreert met Apache Kafka en het kan eenvoudig worden uitgevoerd op Azure met HDInsight of Azure Databricks. Als alternatief kunnen we gebruik maken van de managed services van Azure. Voor het versturen van berichten kunnen we gebruik maken van Azure Event Hubs. Deze berichten kunnen worden opgehaald en geanalyseerd door Azure Stream Analytics. Deze managed services vereisen minder installatie en bieden mogelijk meer gebruiksgemak.
Zodra de gegevens zijn verwerkt door de streaming pipeline, kunnen deze naar de vereiste locaties worden verzonden. Het kan worden opgeslagen in CosmosDB, verzonden naar een datawarehouse, bijvoorbeeld Azure Synapse Analytics, of gestreamd naar PowerBI voor realtime visualisatie.
Conclusie
Met deze oplossing kun je een nauwkeurig, gecentraliseerd en up-to-date datawarehouse onderhouden, terwijl alle onderdelen van je systeem zelfbesturend zijn.

