

De organisatie waar ik werk is bezig met het bouwen van een consumptie laag voor Business Intelligence. Hiervoor hebben we onderzoek gedaan naar verschillende Data warehousing-oplossingen, waaronder Azure Synapse en Databricks SQL.
Databricks SQL
Databricks SQL, dat onlangs in openbare preview is gegaan, is uniek in die zin dat men er direct Business Intelligence-gerelateerde Data-analyses mee kunt uitvoeren op een Data Lake. Het integreert met tools zoals Power BI en Tableau en biedt een geweldige gebruikersinterface waarbij je direct SQL-query’s kunt schrijven voor het doorzoeken van tabellen die in het Delta Lake staan.
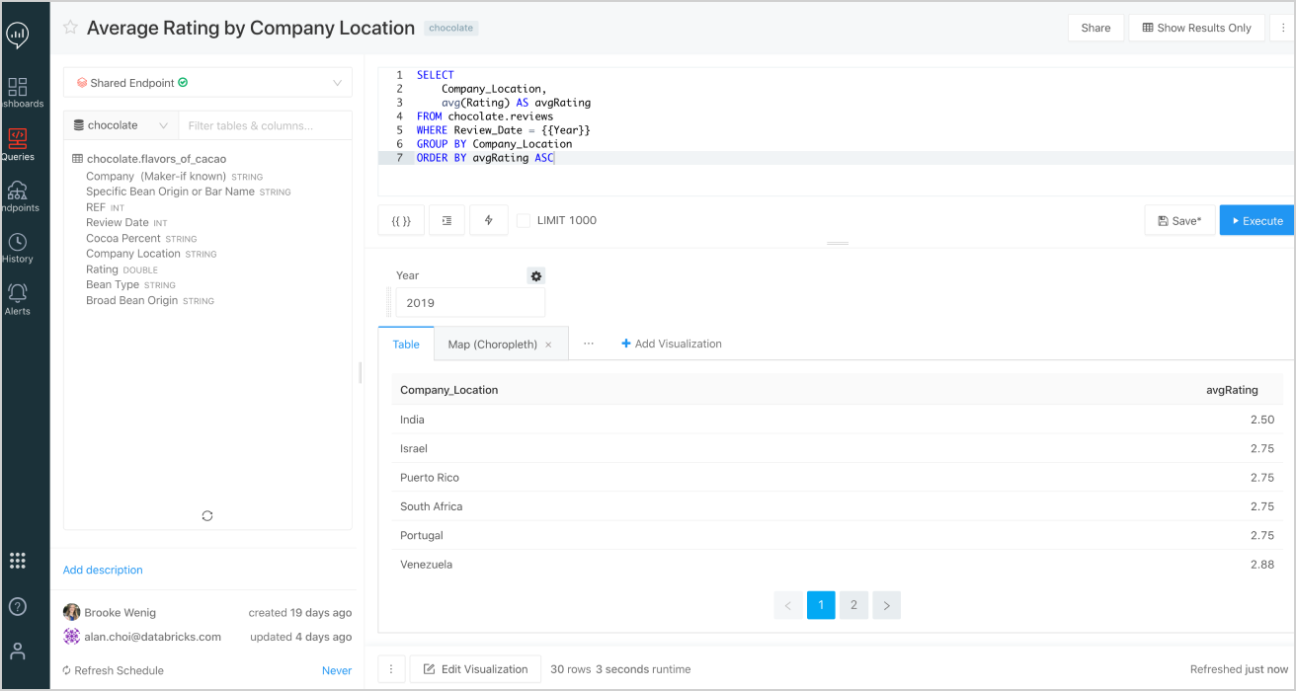
Azure Synapse maakt het tegenwoordig ook mogelijk om gegevens in het Delta Lake rechtstreeks op te vragen met behulp van serverloze pools. Echter is deze functie nog steeds in preview.
We hebben Databricks SQL getest met twee test query’s om tabellen te maken. Beide query’s gebruikten dezelfde drie tabellen als bronnen. Deze tabellen bevatten respectievelijk 205 miljoen, 665 miljoen en 5 miljoen rijen. De vragen zijn groot en omvatten join-, aggregation- en window operations. Hieronder volgen de resultaten voor verschillende clustergroottes voor deze twee query’s (Transacties en TransLines).
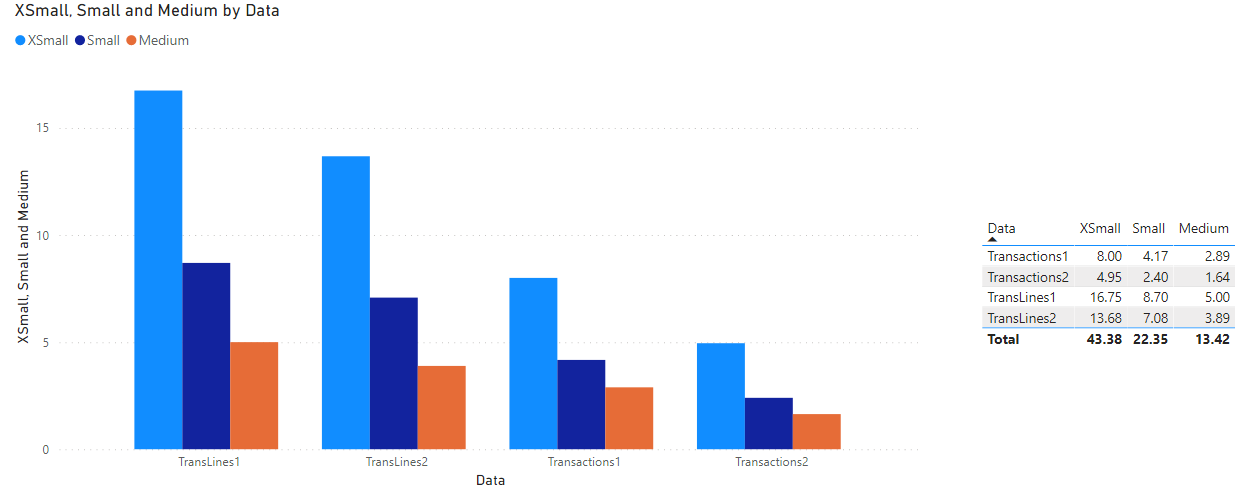
Hier is TransLines meer compute/data-intens omdat TransLines behalve aggregation alleen linker joins omvat. TransLines bevat naast aggregations ook een volledige outer join en een venster bewerking. We hebben de prestaties op twee manieren getest. Ten eerste door de query uit te voeren na het draaien van een cluster en ten tweede wanneer de brontabellen in de cache zijn opgeslagen. Want wat er gebeurt, is dat nadat je een brontabel eenmaal hebt gebruikt, deze in de cache wordt opgeslagen. Ik weet niet zeker wat er precies gebeurt als de brontabel wordt gewijzigd, maar ik kan me voorstellen dat Databricks SQL een manier moet hebben gevonden om alleen de gewijzigde partities bij te werken. In ons geval zijn de gegevens opgedeeld in dagen. Uit het bovenstaande diagram kunnen we zien dat de prestaties erg goed schalen en dat caching echt helpt.
We hebben gemerkt dat caching de prestaties van directe query’s in Power BI aanzienlijk verbeterd. We hebben dat getest met kleinere geaggregeerde tabellen. Dit komt omdat na de eerste keer laden, elke interactie met een rapport/dashboard de gegevens uit de cache haalt.
We hebben ook de prestaties van Databricks SQL vergeleken met Synapse, zoals hieronder weergegeven. Voor Databricks SQL hebben we een middelgrote clustergrootte gebruikt, terwijl we voor Azure Synapse DW1000c hebben gebruikt. De kosten voor beiden zijn vergelijkbaar, waarbij de DW1000c iets hoger is. De resultaten staan hieronder.
We also compared the performance of Databricks SQL with Synapse as shown below. For Databricks SQL, we used a Medium cluster size, whereas for Azure Synapse, we used DW1000c. The cost for both is similar with DW1000c’s being slightly higher. The results are following.
| Query | Executie tijd (minuten) |
| Transactions Synapse (Round Robin distribution) | 3.73 |
| Transactions Synapse (Hash distribution) | 2.13 |
| Transactions Databricks SQL (Not cached) | 2.89 |
| Transactions Databricks SQL (Cached) | 1.64 |
| TransLines Synapse (Round Robin distribution) | Timed out (not completed within 30 minutes) |
| TransLines Synapse (Hash distribution) | 9.03 |
| TransLines Databricks SQL (Not cached) | 5 |
| TransLines Databricks SQL (Cached) | 3.89 |
We zien dat Databricks SQL qua kosten beter presteert dan Azure Synapse. Databricks SQL is echter nog niet zo gepolijst als Azure Synapse en bevindt zich nog steeds in de openbare preview.

