
Met de overstap naar cloud-native applicatiepatronen is het mogelijk geworden om schaalbare en veerkrachtige systemen te bouwen die aan moderne eisen voldoen. We hebben echter gezien dat met deze grote verandering vaak een nog grotere complexiteit komt. Enterprise-grade platformen zoals Red Hat OpenShift komen te hulp en beschermen de ontwikkelaar zoveel mogelijk tegen de complexiteit van onderliggende infrastructuur.
Wat resteert is de kwestie van het monitoren van de honderden microservices, evenals het platform waarop ze worden uitgevoerd. Met veel bewegende delen is de observatieaanpak, ook wel ‘observability’ genoemd in het cloud-native domein, een essentieel onderdeel geworden. In dit blog onderzoeken wij hoe we de observatieaanpak kunnen benutten in het OpenShift Container-platform van Red Hat.
Het belang van observability
Maar eerst, wat betekent observability precies? Mensen gebruiken de termen observability en monitoring vaak door elkaar. In dit blog gaan we niet in op de semantiek. Cindy Sridharan, expert op het gebied van gedistribueerde systemen, bespreekt het onderwerp in haar baanbrekende blogpost ‘Monitoring in the Time of Cloud Native’. Voor mij is waarneembaarheid in een eenvoudige bewoording “het attribuut van een systeem dat gegevens over zichzelf blootlegt die gemakkelijk toegankelijk zijn”. Het is het vermogen om te weten wat er aan de hand is, maar ook waarom. Een ‘observeerbaar’ systeem is een systeem dat zijn vitale statistieken openstelt voor eenvoudige whitebox-bewaking.
“Hoe meer zichtbaarheid u geeft aan mensen, hoe minder toegang u hoeft te geven naar de infrastructuur.” – zegt Kubernetes-goeroe Kelsey Hightower op de KubeCon in Austin, december 2017. Voor technici op de werkvloer uit dit zich in een manier om veilig toezicht te houden op de platform- en diagnosticeer problemen zonder SSH in een machine te hoeven invoeren. Wat ontwikkelaars betreft biedt dit het vermogen om eenvoudig request-flows tussen honderden services te traceren en te correleren.
Promotheus en OpenShift: een perfecte match
Observability is meestal gegroepeerd in drie zogenaamde pijlers: logging, metrics en tracing. Hier richten we ons op metrics, in het bijzonder hoe we metrics van een OpenShift-cluster kunnen onderzoeken door gebruik te maken van de nieuwste versie van Prometheus.
Metrics zijn in de basis aantallen vitale statistieken die met de tijd zijn geaggregeerd. OpenShift neemt de observability, ingebouwd in Kubernetes, over en daarom worden metrics over CPU, geheugen, netwerk, etc blootgesteld aan de kubelet die door Heapster beschikbaar wordt gesteld. OpenShift gebruikt Hawkular als geïntegreerde metriekengine om statistieken te verzamelen en weer te geven met betrekking tot het uitvoeren van pods. Met versie 3.7 van OpenShift is Prometheus toegevoegd als een experimentele functie. Het is de bedoeling om Hawkular als de standaard metriekengine te vervangen in de komende paar releases.
Prometheus is een systeem voor het monitoren van statistieken waarin een cloud-native benadering ingebouwd is voor het monitoren van services. Het is ook een tijdreeksdatabase, een dashboard en een querytaal (PromQL) om de tijdreeks te doorzoeken. De modus operandi van Prometheus is “scraping targets”, of met andere woorden, het trekken van metrische informatie uit geconfigureerde bronnen. Dit wordt gedaan met regelmatige tussenpozen, waarin de mogelijkheid zit om opnieuw te configureren, waarbij deze statistieken als een tijdreeks in de database worden opgeslagen. De Prometheus-community heeft goede documentatie samengesteld met beknopte instructies en best practices.
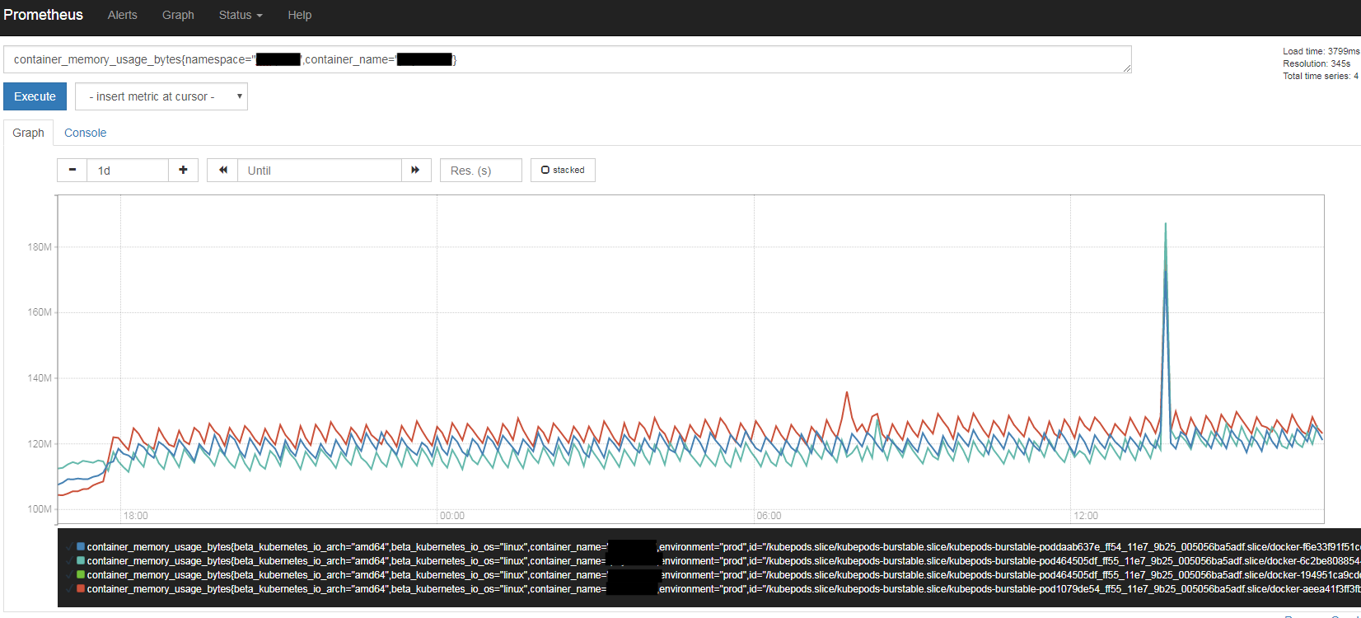
Figuur: Prometheus query browser screenshot
Hoewel Prometheus al een tijdje bestaat, is met de recente uitgave van versie 2.0 een grote stap gezet in de adoptie. Dit heeft onder andere te maken met aanzienlijke verbeteringen in de manier waarop Prometheus omgaat met opslag. Ook was Prometheus het tweede open-sourceproject dat na Kubernetes door de Cloud-Native Computing Foundation (CNCF) werd aangenomen en is in alle opzichten een perfecte fit voor het monitoren van OpenShift.
Het aansluiten van Prometheus en andere componenten
Er zijn verschillende manieren om Prometheus te installeren in OpenShift (hier een mooi voorbeeld). Nog belangrijker is dat de juiste poorten op de clusterknooppunten moeten worden geopend om de Prometheus-pod verbinding te laten maken. Na implementatie kan Prometheus statistieken verzamelen en opslaan die door de kubelets zijn belicht. Natuurlijk kunt u meer doelen configureren (zoals routers, onderliggende knooppunten, enz.), waarbij Prometheus zelfs ook statistieken van deze configuratie mogelijkheden verzamelt. De verzamelconfiguratie wordt in de Prometheus-pod geladen als ConfigMaps. Alle verzamelde statistieken worden lokaal opgeslagen in een tijdreeksdatabase op de ‘node’ waar de pod wordt uitgevoerd (in de standaardinstelling).
Om statistieken te verzamelen vanuit uw eigen applicatie, kunt u gebruik maken van de ‘client libraries’ die op de Prometheus-website staan. U kunt ze gebruiken om Prometheus-metrics te instrumenteren en ze bloot te stellen vanuit uw eigen toepassing, meestal via een eindpunt / metrics. Voor operators is het handig om meer informatie te hebben over onderliggende nodes dan enkel de informatie die worden weergegeven door de kubelets. Hiervoor kunt u gebruik maken van node-exporter, waarmee u hardware- en OS-statistieken kunt verzamelen. Meer exporteurs voor verschillende metrische bronnen staan vermeld op de Prometheus-website.
Hoewel we gegevens kunnen verzamelen en opslaan met Prometheus, moeten we ook waarschuwingsfuncties en dashboarding instellen voor clusteroperaties. Waarschuwingen kunnen ingesteld worden via Alertmanager, wat gebruikt kan worden om waarschuwingen naar externe waarschuwingssystemen, e-mail, slack, pagerduty en andere berichtgevingstools te activeren. Voor dashboarding wordt Prometheus geleverd met een eenvoudige query- en grafische functie, alhoewel het gebruikelijk is om een volledig uitgeruste dashboardtool zoals Grafana te integreren.
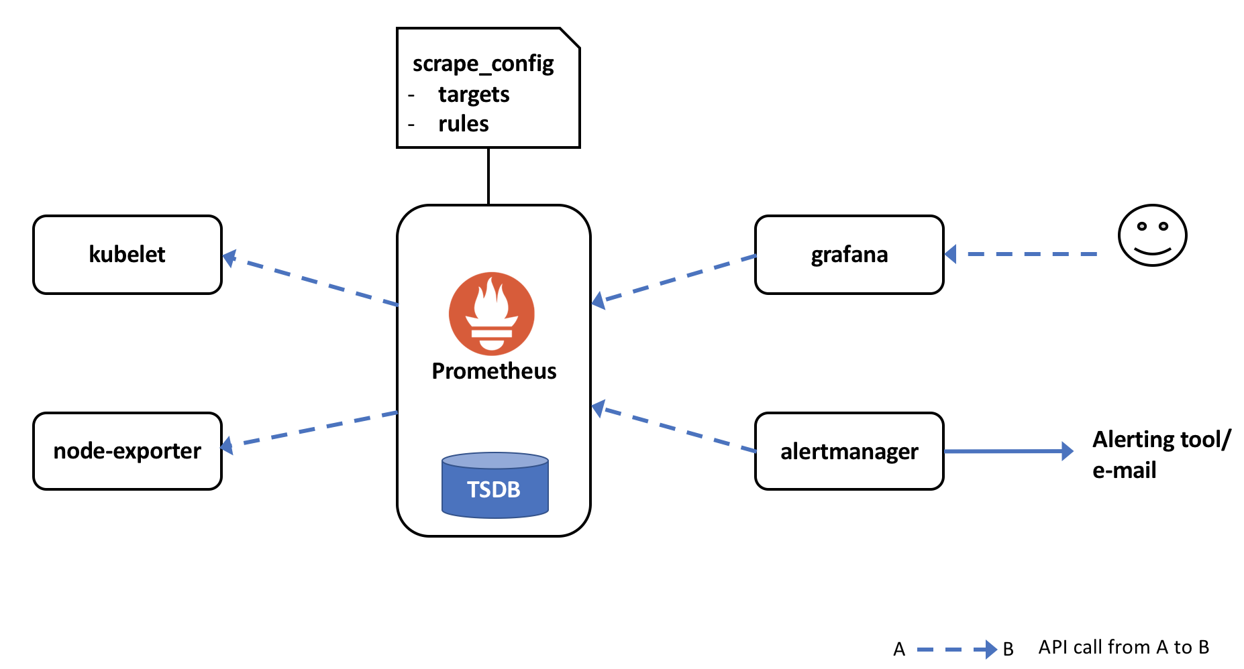
Figuur: Example topology with Prometheus, alertmanager, node-exporter and Grafana in OpenShift
Een punt om rekening mee te houden is dat Prometheus niet is gebouwd voor langdurige opslag. Dus voor het verzamelen van lange-termijnstatistieken, moeten adapters gebruikt worden om de metrics naar externe databases zoals InfluxDB te sturen. Gehoopt wordt dat lange-termijn opslagcapaciteit ingebouwd wordt in OpenShift wanneer de Prometheus-integratie de status van volledige functionaliteit bereikt.
Verkrijg bruikbare informatie
Gewapend met de nodige monitoringtools, komen we nu bij het onderwerp “wat te controleren”. Voor applicaties zijn de meest interessante statistieken om mee aan de slag te gaan het aantal verzoeken, reactietijden, foutenpercentages, enzovoort. Dit naast de specifieke gevallen die speciaal onderzoek behoeven. Voor operations is er de mogelijkheid om cpu, geheugen, latentie en vrijwel alles wat de kubelet en andere exporteurs kunnen bieden te bekijken. Van individuele containers tot clusterbrede scopes. Informatie over het gebruik van bronnen is handig om quota’s en beslissingen over clusteruitbreiding te creëren/nemen. Een leuk aspect van Prometheus is dat OpenShift selectors als filters gebruikt kunnen worden tijdens het zoeken naar tijdreeksen. De Prometheus-querybrowser is zeer gebruiksvriendelijk en biedt eindeloze mogelijkheden. Waarschuwingsfuncties kunnen worden ingesteld op de verzamelde statistieken om problemen proactief te detecteren. De uitgevoerde observatie moet niet alleen helpen om terug te gaan naar wat er in het verleden is gebeurd, maar ook om toekomstige prestaties te verbeteren.
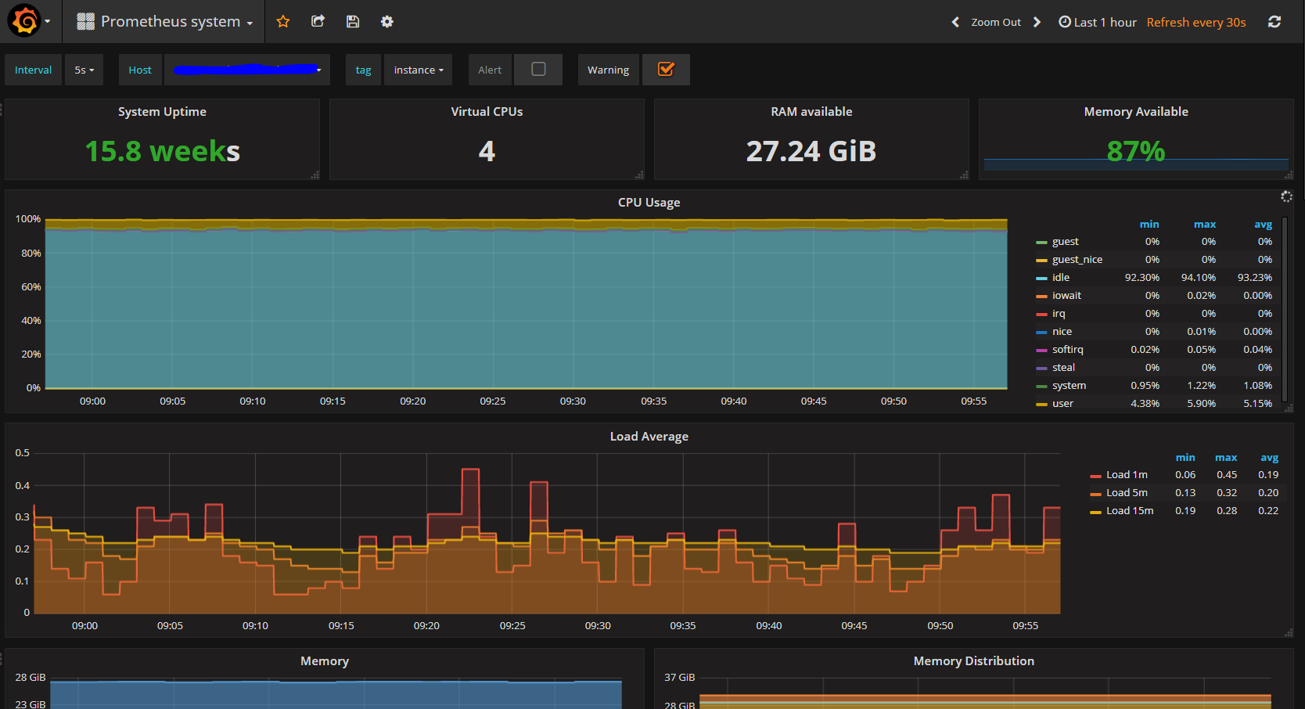
Figuur: A Grafana dashboard based on Prometheus metrics collected from node-exporter
Zoals eerder vermeld, gaat Red Hat duidelijk op weg naar een op Prometheus gebaseerde metrics-engine voor toekomstige versies van OpenShift, wat een goed teken is. OpenShift heeft al een goede logging-infrastructuur met zijn geïntegreerde EFK (Elasticsearch-Fluentd-Kibana) stack. Ook heeft Red Hat plannen om tracing- en service mesh-oplossingen op te nemen in het OpenShift-platform, waarmee observability over alle drie de pijlers in zicht komt.
Meer informatie over observability?
Voor vragen over dit blog kunt u contact opnemen met Gopal Ramachandran, DevOps Consultant bij Devoteam Nederland (gopal.ramachandran@devoteam.com). Meer over dit onderwerp? Bezoek onze DevOps pagina.

