Anticipeer en kijk voor- én achteruit om te weten wat er speelt!
Mijn ervaring leert mij dat er bij veel bedrijven, instellingen of afdelingen onvoldoende gekeken wordt naar data over tijd als het over observability of monitoring gaat. En dat is zonde, want inzicht in data, herkennen en daadwerkelijk zien van trends is iets wat een groot verschil kan maken. Kijken naar informatie van nu zegt niets over de informatie van een uur of dag geleden, of wat komen gaat.
Zaken inzichtelijk maken is iets wat mij altijd al heeft gefascineerd. Vragen beantwoorden op basis van zichtbare feiten, of juist op zoek gaan naar nieuwe inzichten, dat is wat mij drijft.
Inzicht in trends
Inzicht krijgen in trends & analyse over tijd is niet altijd even makkelijk. Product owners / Service Managers willen graag inzicht in applicatie logs of applicatie data. Anderen willen inzicht in de infrastructuur, zoals serverlogs, errorlogs, netwerklogs, CPU en memory usage, of combinaties hiervan. Afhankelijk van de vraag of omgeving waarin je je bevindt is de combinatie van gegevens anders.
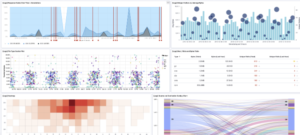
Het doel is steeds hetzelfde: Wanneer is er iets gebeurd, is dit vaker gebeurd en wat was de oorzaak? Is er groei of juist afname en op welke uren of dagen was dit dan het geval?
Met name filteren van data t.o.v. de totalen geven een extra goed inzicht in de trendlijn.
Waardevolle informatie
Onderstaande grafieken zouden bijvoorbeeld data kunnen weergeven van een API Management platform waarbij naar zowel service data (transaction duration, errors en requests per minute) en infrastructuur gegevens wordt gekeken.
Trends over tijd zijn waardevol bij normale operatie, introductie van nieuwe features of misschien wel een sale event. Persoonlijk vindt ik de combinatie applicatie data en infrastructuur data het meest interessant. Is de performance van de applicatie en infrastructuur nog goed bij een hoge load? Of zie je juist dat de applicatie onder druk komt te staan bij een sale event, en hoe was dat t.o.v. de vorige periode? Trendlijnen over een langere tijd geven inzicht en duidelijkheid.
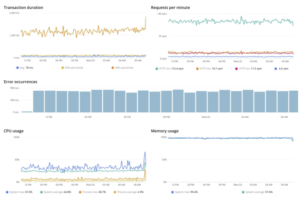
Hoe om te gaan met pieken?
Het kan voorkomen dat er pieken ontstaan in errors en dalingen van orders door technische problemen (onderliggende infrastructuur). Dit kan komen door verschillende omstandigheden of afhankelijkheden die een ritme verstoren.
Sale Event
Blackfriday, CyberMonday en feestdagen zijn momenten waarop pieken te zien zijn in online aankopen. Als een verwachte piek van API transacties uit blijft kan dit meerdere redenen hebben. De website van een winkel kan de drukte niet aan of er is een probleem in het online betaalsysteem. Door in te zoomen op bepaalde uren en deze vergelijken met vergelijkbare momenten kan je tot zeer bruikbare inzichten komen.
Verandering in werken vanwege Corona crisis
Sinds begin dit jaar zijn veel mensen meer of volledig thuis gaan werken. Dit heeft ongetwijfeld geleid tot problemen op authenticatie systemen en diensten. Ongetwijfeld is het gebruik toegenomen, maar is de performance voldoende? Is de load balancer goed ingericht of waar hebben we de meeste problemen? Performance per realm, of gewoon authenticatie data zal zicht geven op trends.
Door de data in een Centralized Monitoring tool te hebben kan je de data zichtbaar maken en omtoveren tot bruikbare handvaten. Wat is de trend en wat zijn de influencers hierbij. Door de data te visualiseren voor verschillende use cases kunnen we tot antwoorden en inzichten komen.
De ELK stack als tool voor Trend Analyse
Met Elasticsearch heb je een hele mooie set aan tools voorhanden die het inzicht kunnen geven in trends & analyse over tijd. De ELK stack (Elasticsearch, Logstash en Kibana) is precies voor dit doel gemaakt:
Je hebt zicht op:
- Infrastructuur metrics
- (Web) Server logs
- Applicatie logs
- Applicatie performance
- Security (SIEM)

Door data en logs op een centrale plek te verzamelen (centralized monitoring) wordt het voor veel vragen (use cases) ineens makkelijk om inzicht te krijgen in de trends & anlyse over tijd. Het is een soort hefboom die je gebruikt, een kracht uitoefenen die je eigenlijk niet hebt. Zo werkt het met Elasticsearch ook. Je laat het het systeem informatie opslaan, indexeren en verdelen. Je kan d.m.v. zoekopdrachten, gebruikmakend van de tijdlijn, iets doen wat je zonder Elasticsearch niet kan.
Servicedesks of monitoring teams kunnen snel verbanden leggen of inzien waardoor een incident wordt veroorzaakt en zo effectieve maatregelen nemen. Snel reageren door slimme alerts bijvoorbeeld.
Als je geen duidelijk overzicht of dashboard hebt kan dit er voor zorgen dat je:
- Niet of veel te laat reageert op een trend
- Niet snapt wat de problemen zijn of waarom er klachten zijn
- Geen terugkerende problemen kan herkennen
Door melding van het monitoring systeem SMART te maken kan je op tijd op de hoogte worden gebracht van een situatie of specifieke use case waarop je wilt acteren.
De oplossing: Elastic Centralized Monitoring
DevOps teams, en Business owners of product owners van uiteendlopende applicaties en systemen kunnen d.m.v. Centralized Monitoring (ELK Stack) inzien wat er gebeurt. Systeem administrators hoeven geen onnodige tijd te verspillen om tientallen of honderden logs na te zoeken waar een probleem zich heeft voorgedaan. Data is centraal beschikbaar in Elasticsearch indices en worden door index patterns bij elkaar gevoegd. Met een zoekopdracht spit je talloze logs door.
Een voorbeeld uit de praktijk
Een team met applicatie- en systeembeheerders bij één van onze klanten had geen inzicht in de load balancing van hun authenticatie systeem op productie. Door de logs van administratie en production servers via logstash naar Elasticsearch te indexeren werd het mogelijk om hier inzicht in te krijgen. Door de data op een histogram te splitsen op hostnaam, kregen zij inzicht in het aantal transacties per server.
Toen de data eenmaal beschikbaar was heb ik ook de authentication succesratio over tijd gemaakt in tijdlijn. Door van de rekenkracht van Elasticsearch gebruik te maken in een tijdlijn, of in TSVB (Time Series Visual Builder), is er inzicht gekomen in het percentage geslaagde en foutieve authenticatie pogingen. Doordat codes moeten worden ingevoerd van je telefoon in de browser type je wel eens fout. Leuk om te zien is dat het ‘s avonds en ‘s nachts veel vaker fout gaat: tot rond de 50% succes van de inlogpogingen.
Dit vind ik een zeer fraai voorbeeld van trends & analyse over tijd. Deze input zou je dus kunnen gebruiken om na te denken over een oplossing hoe je ‘s nacht het inlog percentage omhoog kan krijgen.
Bij Devoteam vinden we het cruciaal dat u controle heeft over uw IT-landschap en bedrijfsactiviteiten. Wij zien centralized monitoring als dé oplossing om u de leiding te geven. Dit doen we met Elastic, onze vertrouwde partner en marktleider in monitoring oplossingen. Samen passen we waardetoevoegende technologie op schaal toe, op basis van bewezen successen bij klanten als Renewi en De Watergroep.
Aarzel niet om contact op te nemen met ons team van experts voor vragen of om een gratis (real-life case) centralized monitoring demo met Elastic aan te vragen.
Gerelateerde content
- Meer info: Why Centralized Monitoring with Elastic?
- Webinar: Elastic Observability bij De Watergroep door Devoteam
- Case study: Observability bij De Watergroep – Van slechtziende mol naar adelaarszicht
- Case study: Integration as unifying factor of digital transformation at De Watergroep
- Blog-post: Waarom Elastic Logstash als Bot gebruiken?
- Blog: Business Function Monitoring

