Regarding the title of this blog, I’m fully aware that there are many ways to achieve loading data to the MySQL server using Python. The actual purpose of this blog is to share more than just simply describing a way to finish this task. Instead, I want to show the logic behind the code I wrote for loading data to the MySQL server.
So a few months ago I got an assignment to load some data from an open data source to a MySQL server on Linux. First I finished the assignment by implementing a very short piece of code. Later on, I changed it to what it currently is. My thought process was as follows:
Am I solving A question or a Type of question?
The current demand was to build a connection to a database. But what if I have to switch between multiple databases in the future? As it was possible for this to happen, defining a class would a safe choice to prevent troubles in the future.
In the following code, I imported a create engine from the SQLAlchemy package to build a connection to the MySQL server. The credentials for the connection are read from a separate file (as in the current case there is only one database connection). However, if you don’t like 100% automation and you want to have more control, setting up user input is also a possibility (as the second line shows, which I put there as a comment for now).

Do I need to save a copy locally?
It’s not that difficult to load data directly to the MySQL server. You can simply write your data to a data frame and load it to the MySQL server within 10 lines.

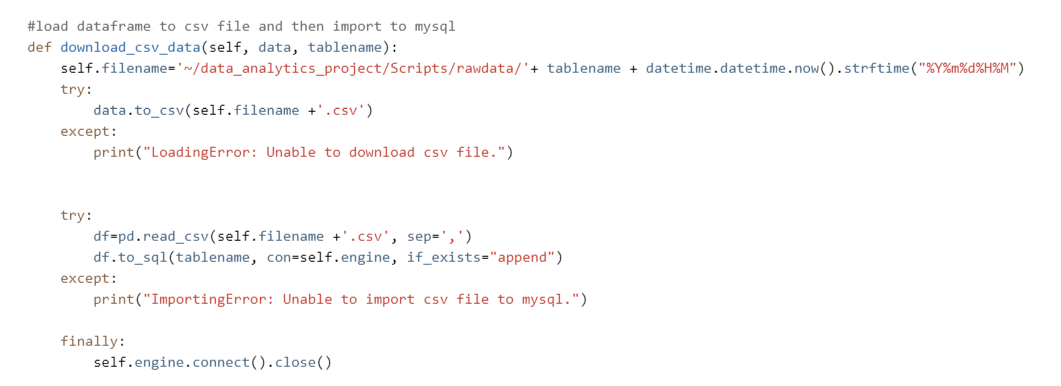
Nevertheless, it would be helpful if we have a local copy. So if anything goes wrong, you can always go back to check what you initially loaded instead of cursing. Therefore, I chose to load the data to a csv file first, after which I loaded the csv file to the MySQL server. Additionally, the csv file’s name is tailed with a timestamp.
“If something can go wrong, it will.” – Murphy’s Law
By embedding “try-except” to all possible breakdowns, we save a lot of potential debugging time. The difficult part here is not in writing the code but forecasting all possible situations and scenarios instead. This requires not only solid technical skills but also a full understanding of the specific case you are on.
The full code on my GitHub
Just in case the code blocks were not clear for you, please visit my GitHub where you can view the code in one piece.

